内置例程
该主题描述创建数据库时被数据库服务器所知的标识符的例程,但是其用法与第 4 章描述的内置 SQL 函数有所不同。
内置例程可以根据它们执行的任务分类:
- 会话配置过程
- SYSDbClose( )
- SYSDbOpen( )
- DataBlade 模块管理函数
- SYSBldPrepare( )
- SYSBldRelease( )
- Visual Explain 输出生成函数
- Explain_SQL( )
- UDR 定义例程
- ifx_Replace_Module( )
- ifx_Unload_Module( )
- jvpControl( )
- sqlj.Alter_Java_Path( )
- sqlj.Install_jar( )
- sqlj.Remove_jar( )
- sqlj.Replace_jar( )
- sqlj.SetUDTExtName( )
- sqlj.UnsetUDTExtName( )
- sysgbase.Metadata( )
- sysgbase.sqlcaMessage( )
如果数据库服务器配置为支持 DRDA 协议,则会自动创建 Metadata 和 sqlcaMessage 例程。SYSDbOpen 和 SYSDbClose 例程可以在任一 GBase 8s 数据库中定义。
随后的章节描述了这些类别和每个类别中的例程。
间隔函数
使用间隔函数从包含表示 INTERVAL 限定符中的时间单位和分隔符的数字和字符串的参数中返回 INTERVAL 值。这些函数在定义或修改索引和表的范围间隔分布式存储策略的 CREATE TABLE 、CREATE INDEX 和 ALTER FRAGMENT 语句中非常有用。
间隔函数将数字或字符串转换为 INTERVAL DAY TO SECOND 或 INTERVAL YEAR TO MONTH 字面值,或第二个参数中指定的时间单位的有效精度。然而,这些函数不支持 FRACTION 或 .FRACTION 作为它们的第二个参数中的最后一个时间单位。
TO_DSINTERVAL 函数
TO_DSINTERVAL 函数将表示时间单位的字符串转换为 INTERVAL DAY TO SECOND 字符值。此函数还可以接受数字和字符串作为其参数,并以单个时间单位精度 DAY 、HOUR 、MINUTE 或 SECOND 返回 INTERVAL 值。
当您定义范围间隔存储分配策略以分片表或索引时,您可以使用单个参数(或两个参数,其同义词 NUMTODSINTERVAL)的 TO_DSINTERVAL 函数来指定间隔范围值。
语法
数字转换为 INTERVAL

字符串转换为 INTERVAL
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| DD | 一位或两位数指定间隔中的天数 | 必须是下列其中之一的数据类型: ● CHAR ● NCHAR ● VARCHAR ● NVARCHAR ● LVARCHAR | 字符串 |
| HH:MM:SS | 三组两位数字,用冒号(:)符号分隔,指定间隔中的小时数、分钟数和秒数 | 必须是下列其中之一的数据类型: ● CHAR ● NCHAR ● VARCHAR ● NVARCHAR ● LVARCHAR | 字符串 |
| number | 指定间隔中的天数、小时数、分钟数或秒数的数字。 可以是表达式,包括列表达式,该表达式解析(或转换)到其中一个有效数字数据类型。 | 必须是下列其中之一的数据类型: ● INT ● BIGINT ● SMALLINT ● INT8 ● DECIMAL ● REAL ● FLOAT ● SERIAL ● SERIAL8 ● BIGSERIAL | 数值 |
用法
当您使用结果分片表或索引时,可以使用 TO_DSINTERVAL 函数指定间隔值。TO_DSINTERVAL 函数在允许内置例程的上下文中有效。NUMTODSINTERVAL 函数与 TO_DSINTERVAL 函数相同都是用来转换数字值。
以下示例显示了 TO_DSINTERVAL 函数是如何解释不同的值:
以下示例指定一天的间隔:
TO_DSINTERVAL('1 00:00:00')
TO_DSINTERVAL(1,'DAY')
NUMTODSINTERVAL(1,'DAY')
以下示例指定一个小时的间隔:
TO_DSINTERVAL('0 01:00:00')
TO_DSINTERVAL(1,'HOUR')
NUMTODSINTERVAL(1,'HOUR')
以下示例指定一分 30 秒的间隔:
TO_DSINTERVAL('0 00:01:30')
TO_DSINTERVAL(1.5,'MINUTE')
NUMTODSINTERVAL(1.5,'MINUTE')
以下示例显示了如何使用表达式作为数字值:
TO_DSINTERVAL(10+10+100,'DAY')
TO_YMINTERVAL 函数
TO_YMINTERVAL 函数将表示时间单位的字符串转换为 INTERVAL YEAR TO MONTH 字符值。此函数还可以接受数字和字符串作为其参数,并返回具有单位时间单位精度 YEAR 或 MONTH 的 INTERVAL 值。
当您定义范围间隔存储分配策略以分片表或索引时,您可以使用单个参数(或两个参数,其同义词 NUMTODSINTERVAL)的 TO_DSINTERVAL 函数来指定间隔范围值。
语法
数字转换为 INTERVAL

字符串转换为 INTERVAL
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| number | 间隔中的年或月的数字。 可以是表达式,该表达式解析(或强制转型)到其中一个有效数字数据类型。 | 必须是下列其中之一的数据类型: ● INT ● BIGINT ● SMALLINT ● INT8 ● DECIMAL ● REAL ● FLOAT ● SERIAL ● SERIAL8 ● BIGSERIAL | 数字 |
| MM | 指定间隔中月数的两个数字。连字符(-)必须在第一个数字之前。 | 必须是下列其中之一的数据类型: ● CHAR ● NCHAR ● VARCHAR ● NVARCHAR ● LVARCHAR | 字符串 |
| YY | 指定间隔中年数的两个数字 | 必须是下列其中之一的数据类型: ● CHAR ● NCHAR ● VARCHAR ● NVARCHAR ● LVARCHAR | 字符串 |
用法
当按间隔分片表或索引时,可以使用 TO_YMINTERVAL 函数指定间隔值。TO_YMINTERVAL 函数在允许内置例程的上下文中有效。NUMTOYMINTERVAL 函数与 TO_YMINTERVAL 函数相同都是用来转换数字值。
示例
以下示例显示了 TO_YMINTERVAL 是如何解释不同的值的。
以下示例指定一年的间隔:
TO_YMINTERVAL('01-00')
TO_YMINTERVAL(1,'YEAR')
NUMTOYMINTERVAL(1,'YEAR')
以下示例指定一个月的间隔:
TO_YMINTERVAL('00-01')
TO_YMINTERVAL(1,'MONTH')
NUMTOYMINTERVAL(1,'MONTH')
以下示例指定一年零六个月的间隔:
TO_YMINTERVAL('01-06')
TO_YMINTERVAL(1.5,'YEAR')
NUMTOYMINTERVAL(1.5,'YEAR')
以下示例显示如何使用表达式作为数字值:
TO_YMINTERVAL(10+10+100,'YEAR')
以下示例定义了具有范围间隔分片模式的表 t2 。这里的 DATETIME 列 dt1 是分片键,NUMTOYMINTERVAL 的返回值将间隔大小定义为 25 年。具有年份晚于 2005 年但早于 2031 的 dt1 值的行将存储在范围分片 p1 中:
CREATE TABLE t2 (c1 int, d1 date, dt1 DATETIME YEAR TO FRACTION)
FRAGMENT BY RANGE (dt1) INTERVAL (NUMTOYMINTERVAL (25,'YEAR'))
PARTITION p1 VALUES <
DATETIME(2006-01-01 00\:00\:00.00000) YEAR TO FRACTION(5) IN dbs1;
如果插入一行,其中 dt1 中的 YEAR 值小于 2006 或大于 2030,那么数据库服务器将会自动创建一个新的间隔分片,其范围大小是 25 年。有关范围间隔分片的语法和语义的更多信息,请参阅 Interval fragment 子句。
会话配置过程
这些内置 SPL 过程使数据库管理者在用户连接数据库或从数据库断开连接时,自动执行 SQL 和 SPL 语句。
在本手册中这些例程称为内置过程,因为数据库服务器识别它们的名称,并且将它们与处理其它例程的方式区别对待,但数据库服务器不会自动创建这些例程。要使用其特性,DBA 必须发出 CREATE PROCEDURE 语句或 CREATE PROCEDURE FROM 语句来定义这些例程的操作并将其注册到数据库中。只有 DBA 或用户 gbasedbt 可以创建、更改或删除这些例程。
如果 DBA 指定用户的登录 ID 作为其中一个过程的所有者,那么当指定的用户连接数据库或从数据库断开连接时数据库服务器会指定执行它。如果 DBA 指定 PUBLIC 作为所有者,则当不是任何这些内置会话配置过程的所有者的用户连接到数据库或从数据库断开连接时,将自动执行该例程。同一数据库服务器实例的不同数据库可以为单个用户或 PUBLIC 指定相同或不同的会话配置过程。这些内置过程在设置会话环境或激活代码无法轻易修改的应用程序的用户角色时非常有用。
这些是内置会话配置过程:
- sysdbclose
- sysdbopen
使用 SYSDBOPEN 和 SYSDBCLOSE 过程
要为一个或多个会话设置初始环境,创建并安装 sysdbopen() SPL 过程。该过程的典型影响是初始化会话的属性,而不需要在会话中显式定义属性。
如果用户通过不能修改应用程序代码或设置环境选项或环境变量的客户端应用程序访问数据库,则为一个或多个会话设置初始环境非常有用。
只要用户成功发出 DATABASE 或 CONNECT 语句以显式连接到安装了过程的数据库,就会执行 sysdbopen 过程。(但是当连接到本地数据库的用户调用远程 UDR 或执行通过使用 database:object or database@server:object 符号引用远程数据库对象的分布式 DML 操作是,不会在远程数据库中调用 sysdbopen 过程。)
这些过程时一般规则的例外情况,当在与 ANSI 不兼容的数据库中调用例程时, GBase 8s 会忽略 UDR 所有者的名称。对于除 sysdbopen 和 sysdbclose 之外的 UDR ,具有相同的 SQL 标识符但不同所有者名称的 UDR 的多个版本不能在同一数据库中注册,除非创建数据库的 CREATE DATABASE 语句也包括 WITH LOG MODE ANSI 关键字。
还可以创建 sysdbclose SPL 过程,当用户发出 LOSE DATABASE 或 DISCONNECT 语句从数据库断开连接时执行此过程,如果 PUBLIC**.sysdbclose** 过程已在数据库中注册,并且没有为当前用户注册 user**.sysdbclose** 过程,则当该用户与数据库断开连接时,将自动执行 PUBLIC**.sysdbclose** 过程。
您可以打开或关闭数据库时包含适当的有效 SQL 或 SPL 语言语句。对 SPL 过程中有效的 SQL 语句的一般限制也适用于这些例程。有关 SPL 例程中的 SQL 和 SPL 语句的限制,请参阅以下各节:
- SPL 语句的子集在语句r块中有效。
- SQL 语句在 SPL 语句块中有效。
- 在数据操纵语句中 SPL 例程的限制。
sysdbopen 和 sysdbclose 过程是存储过程的作用域规则的例外。在一般 UDR 过程中,变量和语句的范围是局部的。当这些 SPL 过程退出时,SET PDQPRIORITY 和 SET ENVIRONMENT 语句设置不会保留。但是,在 sysdbopen 和 sysdbclose 过程中,设置会话环境的语句将保持有效,直到另一个语句重置选项,或会话结束。
例如,以下过程将事务隔离级别设置为 Repeatable Read,并设置 OPTCOMPIND 环境变量以指示查询优化器优先选择嵌套循环连接。当没有 user**.sysdbopen** 过程的用户连接到数据库时,将执行此例程:
CREATE PROCEDURE public.sysdbopen()
SET ISOLATION TO REPEATABLE READ;
SET ENVIRONMENT OPTCOMPIND '1';
END PROCEDURE;
过程不接受参数和返回值。sysdbopen 和 sysdbclose 过程必须在您希望执行的数据库中注册。DBA 可以创建以下四个类别的 sysdbopen 和 sysdbclose 过程。
过程名 描述
user.sysdbopen 当指定的 user 将数据库作为当前数据库打开时执行此过程。
public.sysdbopen 如果没有应用 user.sysdbopen 过程,那么当将数据库作为当前数据库打开时执行此过程。要避免重复的 SPL 代码,您可以供用户指定的过程调用此过程。
user.sysdbclose 当指定的 user 关闭数据库时执行此过程,从数据库断开连接,或者解释用户会话。但是,如果当会话打开数据库时 user.sysdbclose 不存在,那么当会话关闭数据库时不会执行此过程。
public.sysdbclose 如果没有应用 user.sysdbclose 过程,则当用户关闭数据库服务器或从数据库服务器断开连接或结束会话时执行此过程。但是,如果当会话打开数据库时,public.sysdbopen 不存在,则当会话关闭数据库时不会执行此过程。
如果 CLOSE DATABASE 或 DISCONNECT 语句显式地终止连接,则数据库服务器调用 user.sysdbclose 过程(如果它在数据库中存在)或 public.sysdbclose (如果它存在并且不被用户使用)。如果应用程序在不发出 CLOSE DATABASE 或 DISCONNECT 语句的情况下终止,则数据库服务器强制执行数据库的隐式关闭,并执行 sysdbclose 过程(如果有该名称的 UDR 由用户或 PUBLIC 拥有)。
请确保正确设置文件访问权限,以允许预期用户执行 SPL 过程语句。例如,如果 SPL 过程执行将输出写入本地目录的命令。则必须设置权限以允许用户写入此目录。如果希望在许可失败时继续该过程,请为此条件包含 ON EXCEPTION 错误处理程序。
有关可以出现在 SPL 例程中的 SQL 语句以及有关事务和角色的 SPL 支持的更多信息,请参阅语句块一节。
如果 sysdbclose 过程失败,该失败会被忽视。然而,如果 sysdbopen 过程失败,数据库不会被打开。
为了避免无法打开数据库的情况,请在编写和调试 sysdbopen 过程时采取以下预防措施:
在连接到数据库之前设置 IFX_NODBPROC 环境变量。当设置 IFX_NODBPROC 时,不会执行该过程,并且故障不能阻止数据库打开。
来自这些过程的故障可以有系统生成或由 SPL 的 RAISE EXCEPTION 语句在过程中进行模拟。如果在连接时为用户调用的 sysdbopen 例程包含此语句,则该用户无法连接到数据库。有关更多信息,请参阅 RAISE EXCEPTION 的描述。
出于安全原因,非 DBA 无法阻止这些过程的执行。然而,对于一些应用程序,例如 ad hoc 查询应用程序,用户可以执行随后该表环境的命令和 SQL 语句。
sysdbopen 过程中定义的缺省角色优先于用户建立与数据库的连接时用户持有的任何其它角色,其中 sysdbopen 成功地为该用户指定了缺省角色。
由 user.sysdbopen 或 user.sysdbclose 过程中的 DDL 语句创建的任何数据库对象都由连接的用户所有,并且在 PUBLIC.sysdbopen 或 PUBLIC.sysdbclose 内创建的任何对象都由 PUBLIC 用户标识拥有,除非对象名称在 DDL 语句中声明时,被某个其它所有者名称完全限定。
对于兼容 ANSI 的数据库,在 CREATE PROCEDURE 语句的 sysdbopen 或 sysdbclose 定义的末尾需要显式的 COMMIT WORK 语句,以防止 sysdbopen 或 sysdbclose 过程执行的 SQL 语句的任何隐式事务在终止过程时回滚。(省略 COMMIT WORK 语句不会导致连接失败,但会在打开和回滚事务时浪费资源。)
有关这些过程中无效的 SQL 语句的列表,请参阅 SQL 语句在 SPL 语句块中有效。有关在这些过程中有效的 SPL 语句,请参阅 SPL 语句的子集在语句块中有效。
有关如何编写和安装 SPL 过程的一般信息,请参阅 GBase 8s SQL 教程指南中 SPL 例程一节。
在连接和访问时配置会话属性
可以使用 sysdbopen( ) 过程在连接或访问时更改数据库服务器会话的属性。如果无法修改应用程序的源代码以设置环境选项或会话变量,或者包括会话相关的 SQL 语句(例如,因为 SQL 语句包含供应商获取的代码),这将非常有用。
要更改会话的属性,请为各种数据库设计自定义 sysdbopen( ) 和 sysdbclose( ) 过程,以支持特定用户或 PUBLIC 组的应用程序。sysdbopen( ) 和 sysdbclose( ) 过程可以包含数据库服务器为用户或 PUBLIC 组在数据库打开或关闭时执行的 SET 、SET ENVIRONMENT 、SQL 或 SPL 语句的序列。
例如,对于 user1,您可以定义包含在 user1 使用 DATABASE 或 CONNECT TO 语句打开数据库时执行的 SET PDQPRIORITY 、SET ISOLATION LEVEL 、SET LOCK MODE 、SET ROLE 或 SET EXPLAIN ON 语句的过程。
由于 sysdbopen( ) 过程中的 SET ENVIRONMENT 语句指定的会话环境变量 PDQPRIORITY 和 OPTCOMPIND 的任何设置将在会话持续时间内保持不变。SET PDQPRIORITY 和 SET ENVIRONMENT OPTCOMPIND 语句(对于常规过程不持久)在 sysdbopen( ) 过程中包含它们。
当作为过程所有者的用户从数据库断开连接时(或者 PUBLIC.sysdbclose( ) 运行时,如果它存在且当前用户不拥有 sysdbclose( ) 过程,运行 user.sysdbclose( ) 过程。
在自定义 sysdbopen( ) 和 sysdbclose( ) 过程中,当在与 ANSI 不兼容的数据库中调用例程时,GBase 8s 不会忽略 UDR 所有者的名称。
配置会话属性
只有 DBA 或用户 gbasedbt 可以在 SQL 的 ALTER PROCEDURE 、ALTER ROUTINE 、CREATE PROCEDURE 、CREATE PROCEDURE FROM 、CREATE ROUTINE FROM 、DROP PROCEDURE 或 DROP ROUTINE 语句中创建或更改 sysdbopen( ) 或 sysdbclose( )。
您可以设置 sysdbopen( ) 过程,在连接或访问时更改会话的属性,而不更改会话运行的应用程序。如果无法修改应用程序的源代码以设置环境选项或环境变量或包括会话相关的 SQL 语句,例如,因为 SQL 语句包含供应商获取的代码,这将非常有用。
按照以下步骤设置 sysdbopen() 和 sysdbclose() 过程以配置会话属性:
- 将 IFX_NODBPROC 环境变量设置为任意值,包括 0,使数据库服务器绕过并阻止 sysdbopen( ) 或 sysdbclose( ) 过程的执行。
- 编写 CREATE PROCEDURE 或 CREATE PROCEDURE FROM 语句定义特定用户或 PUBLIC 组的过程。
- 测试此过程,例如,通过在 EXECUTE PROCEDURE 语句中使用 sysdbclose( )。
- 取消设置 IFX_NODBPROC 环境变量以启用数据库服务器运行 sysdbopen( ) 或 sysdbclose( ) 过程。
SYSDBOPEN 过程的示例
以下过程设置指定用户的角色和 PDQ 优先级,并启用 NOVALIDATE 会话环境变量:
CREATE PROCEDURE oltp_user.sysdbopen()
SET ROLE TO oltp;
SET PDQPRIORITY 5;
SET ENVIRONMENT NOVALIDATE '1';
END PROCEDURE;
以下示例过程设置 PUBLIC 组的角色和 PDQ 优先级,并将 RETAINUPDATELOCKS 会话环境变量设置为 CURSOR STABILITY
CREATE PROCEDURE PUBLIC.sysdbopen()
SET ROLE TO others;
SET PDQPRIORITY 1;
SET ENVIRONMENT
RETAINUPDATELOCKS 'CURSOR STABILITY';
END PROCEDURE
DataBlade 模块管理函数
从连接到支持显式事务日志记录的 GBase 8s 数据库的会话中,可以通过发出调用内置 SYSBldPrepare( ) 的 SQL 函数注册或注销 DataBlade 模块。另一个内置函数,SYSBldRelease( ),返回本地数据库中 SYSBldPrepare( ) 函数的版本字符串。
通过 SQL 函数注册和注销 DataBlade 模块的替代方法是使用 BladeManager 实用程序。BladeManager 实用程序可以执行多种 DataBlade 模块任务,包括注册、注销和显示有关 DataBlade 模块的信息。此实用程序支持命令行界面和图形用户界面。有关使用 BladeManager 实用程序的更多信息,请参阅 GBase 8s DataBlade 模块安装和注册指南。
SYSBldPrepare 函数
SYSBldPrepare( ) 是 GBase 8s 在服务器实例的所有数据库中定义的函数签名。可以使用它注册或注销 DataBlade 模块,另一种方法是使用 BladeManager 实用程序。
SYSBldPrepare( ) 函数具有以下定义:
CREATE FUNCTION gbasedbt.sysbldprepare (CHAR(64), CHAR(18))
RETURNS INTEGER
EXTERNAL NAME '$GBASEDBTDIR/extend/ifxmngr/ifxmngr.bld(SYSBldCustomPrepare)'
LANGUAGE C;
返回的整数表示此函数调用成功(0)或失败(非0)。
以下限制应用于您调用此内置函数的数据库:
- GBase 8s 实例的配置文件中的最小 STACKSIZE 应该至少为 64 K 。(在某些系统中,缺省的 stack 大小为 32K,但是对使用 SYSBldPrepare( ) 函数的数据库推荐使用 64 K )。
- 该函数调用不能引用远程数据库。您只能在当前连接的本地数据库中注册或注销 DataBlade 模块。
- 数据库必须支持显式事务。您不能在兼容 ANSI/ISO 的数据库中调用此函数,或者在不支持事务日志记录的数据库中调用此函数。
- 在 Enterprise Replication 集群环境中,支持数据库的 GBase 8s 实例不能是远程辅助服务器。因为这种服务器不能直接支持 DDL 操作,就像此函数支持的 DDL 操作。如果要在辅助服务器上注册或注销 DataBlade 模块,您必须在辅助服务器复制的主服务器上注册或注销此模块。 .
这是调用 SYSBldPrepare( ) 的语法:
SYSBldPrepare 函数

Module Reference
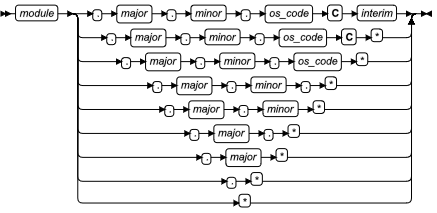
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| module | 要注册或注销的 DataBlade 模块的名称 | 要 'CREATE' module 必须安装在 $GBASEDBTDIR/extend 中。要 'DROP' 它则必须在当前数据库中注册。 | 字符串字符 |
| file | 列出一个或多个 DataBlade 模块的文件的名称,每个模块引用格式 | 必须在 $GBASEDBTDIR/extend/ifxmngr 目录中存在 | Character string with no suffix |
| major | 整数指定主要的 GBase 8s 发布版本 | 必须与已安装或已注册的 DataBlade 模块或通配符的主要版本匹配 | 数字字符 |
| minor | 整数指定 GBase 8s 次要的发布版本 | 必须与已安装或已注册的 DataBlade 模块或通配符的次要版本匹配 | 数字字符 |
| os_code | 支持的操作系统的大写字母代码 | 有效选项为 F 、H 、T 或 U。这些代码在 DataBlade 模块安装与注册指南的第一章中有所描述。 | 文字字符 |
| interim | 整数指定 GBase 8s 临时的发布版本 | 必须与已安装或已注册的 DataBlade 模块或通配符的临时版本匹配 | 数字字符 |
可以使用 SQL 的 EXECUTE FUNCTION 语句或 SPL 的 CALL 语句调用此函数。
SYSBldPrepare( ) 的第一个参数指定要处理的 DataBlade 模块或文件。第二个参数是注册 ('CREATE')还是 注销('DROP')第一个参数必须指定一个 DataBlade 模块,而不是一个文件。
指定 File 作为 First 参数
如果 'CREATE' 是第二个参数,则第一个参数必须是单个模块引用或文本文件的名称,它指定一个或多个模块引用的列表,每个模块引用语法的格式如上面的语法图所示。(但是,此文本文件不能列出列出模块引用的另一个文本文件的名称。)。通过将有效文件指定为第一个参数,可以在单次调用 SYSBldPrepare( ) 函数注册一组 DataBlade模块。
该文件可以是您创建的文件,也可以是数据库服务器创建的 builtin 文件。builtin 文件包括 GBase 8s 分类为内置的 DataBlade 模块的列表。这些内置 DataBlade 您可与 GBase 8s 一起分布,并安装在 $GBASEDBTDIR/extend 文件系统中,但在它们注册到数据库之前无法访问。不支持用户对数据库服务器维护的此 builtin 文件的更新。
模块引用中的版本字符串和星号(*)符号
当第一个参数以 DataBlade 模块的名称开头时,您还可以执行句号( .)分隔符之后的结束版本字符串。 完整的版本字符串与 SQL 的 DBINFO('version full') 函数或 oninit -V 实用程序的返回值的格式相同, 但是它基于 DataBlade 模块的发布版本。
DataBlade 模块名称或版本字符串可以用星号(*)通配符截断。SYSBldPrepare( ) 如何解释星号符号取决于第二个参数:
- 如果 'CREATE' 是第二个参数,则星号与指定模块的最高安装版本匹配。
- 如果 'DROP' 是第二个参数,则星号与在本地数据库中注册的 DataBlade 模块中的模块的注册版本相匹配。在数据库中可以注册给定 DataBlade 模块的最多一个版本 ,因此替换版本字符串的星号指定已注册的版本。
模块引用中不是最后一个字符的任何星号符号都将解释为文字字符,而不是通配符。
其中 SYSBldPrepare( ) 搜索第一个参数指定的模块取决于第二个参数:
- 如果 'CREATE' 是第二个参数,则该函数在安装 $GBASEDBTDIR/extend 目录中的模块之间进行搜索。.
- 如果 'DROP' 是第二个参数,则该函数将在本地数据库中注册的 DataBlade 模块的指定版本。因为在数据库中不能注册多个版本的给定 DataBlade 模块,所以替换版本字符串的星号指定已注册的版本。
注册和注销 DataBlade 模块
此函数的第二个参数必须是 'CREATE' 或 'DROP':
- 使用 'CREATE' 注册第一个参数指定的已安装的 DataBlade 模块(或者一组已安装的 DataBlade 模块)。
- 使用 'DROP' 注销第一个参数指定的已安装的 DataBlade 模块。'DROP' 选项不能在对 SYSBldPrepare( ) 的单次调用中注销多个 DataBlade 模块。
使用 'CREATE' 作为其第二个参数成功调用 SYSBldPrepare( ) 函数还会注册在第一个参数中指定的模块依赖的任何 DataBlade 模块。例如,下面的 SQL 语句注册 8.21.FC2 版本 的 Example DataBlade 模块 ,并在当前数据库中隐式注册了 R-tree DataBlade 模块的最新安装版本,其中 Example DataBlade 模块具有依赖性,如果 R-tree DataBlade 模块尚未在数据库中注册:
EXECUTE FUNCTION sysbldprepare ('example.8.21.FC2', 'create');
但是,如果已经在数据库中注册了相同的 DataBlade 模块的不同发行版本,则如果 'CREATE' 是第二个参数,则mSYSBldPrepare( ) 会升级。例如,上面的函数调用把 Example DataBlade 模块的版本 8.20.FC1 升级到版本 8.21.FC2,如果版本 8.20.FC1 在调用 SYSBldPrepare( ) 时已经在同一个数据库中注册,但是 R-tree DataBlade 模块不会被隐式升级。
以下 SQL 语句使用星号表示法注销在数据库中注册的 Node 扩展的最高版本:
EXECUTE FUNCTION sysbldprepare ('Node.*', 'drop');
与注册操作不同,调用指定 'DROP' 作为第二个参数的 SYSBldPrepare( ) 不会对第一个参数未指定的任何 DataBlade 模块自动生效。'DROP' 参数不会隐式注销与第一个参数指定的模块具有依赖关系的其它 DataBlade 模块。
在事务中使用 SYSBldPrepare( )
SYSBldPrepare( ) 函数在内部使用显式事务。如果发出 BEGIN WORK 以及开始调用 SYSBldPrepare( ) 的事务,则在同一事务中,但在调用 SYSBldPrepare( ) 之前,DML 或 DDL 语句对数据库所做的任何更改的状态是不可预测的。当提交 SYSBldPrepare( ) 的内部事务时,可能会提交来自 DML 或 DDL 操作的更改,从而使您无法通过 SQL 语句的词法顺序中函数调用之后的错误处理逻辑回滚这些更改。要避免此情况,请不要在显式开始的事务中调用 SYSBldPrepare( ) 。
调用 SYSBldPrepare( ) 中的异常
如果尝试使用 'DROP' 选项注销在当前数据库中注册的另一个 DataBlade 模块所依赖的另一个 DataBlade 模块,则 SYSBldPrepare( ) 函数会发出错误。例如,当在注册 Example DataBlade 模块时您不能使用此函数注销 R-tree DataBlade 模块mod。
如果 SYSBldPrepare( ) 试图注销未注册在数据库中的 DataBlade 模块, GBase 8s 也会发出错误。
以下示例显示尝试注册未安装的 DataBlade 模块以及生成的错误消息:
EXECUTE FUNCTION sysbldprepare ('node.2.33', 'create');
(U0001) - registerBlade - Unable to register node.2.33
– DataBlade module not found
- check online log and sysblderrorlog table for more information
如果 IFX_EXTEND_ROLE 配置参数设置为 ON,那么调用此例程的授权仅对数据库服务器管理员(DBSA)和 DBSA 授予的 EXTEND 角色的其它人可用。缺省情况下,DBSA 是用户 gbasedbt。
此函数执行时发生的异常可能导致 SYSBldPrepare( ) 发出不是 GBase 8s 错误消息的诊断错误消息。有关 SYSBldPrepare( ) 可用发出的错误消息的信息,请参阅 GBase 8s DataBlade 模块安装和注册指南 。
SYSBldRelease 函数
SYSBldRelease( ) 是 GBase 8s 在服务器实例的所有数据库中定义的函数签名。你可以使用 SQL 的 EXECUTE FUNCTION 语句或 SPL 的 CALL 语句调用此函数,以返回 SYSBldPrepare( ) 函数的版本字符串。
SYSBldRelease( ) 函数的定义如下:
CREATE FUNCTION gbasedbt.sysbldrelease()
RETURNS LVARCHAR
EXTERNAL NAME
'$GBASEDBTDIR/extend/%SYSBLDDIR%/ifxmngr.bld(MackRelease)'
LANGUAGE C NOT VARIANT;
GRANT EXECUTE ON FUNCTION SYSBldRelease() TO PUBLIC;
该函数不采用参数。它返回版本字符串和 SYSBldPrepare( ) 函数的完成日期。返回的版本字符串具有以下格式:
major.minor.os_codeCinterim
此处的 C 是文字字符,major 、minor 、os_code 和 interim 版本字符串元素具有相同的语义,这些术语包含在 SYSBldPrepare( ) 函数的 Module Reference 段中,但没有星号(*)通配符的表示法。
当通过 SYSBldPrepare( ) 问题联系 GBase 支持时,SYSBldRelease( ) 非常有用。
SYSBldRelease( ) 返回 SYSBldPrepare( ) 正确的版本字符串之前,SYSBldPrepare( ) 函数需要在同一数据库中至少调用一次。对 SYSBldPrepare( ) 的调用不需要在与调用 SYSBldRelease( ) 相同的会话中。
EXPLAIN_SQL 例程
GBase Data Studio Administration Edition 可以使用 EXPLAIN_SQL 例程获得 XML 格式的查询计划、解释 XM 、并且可视化地呈现计划。
GBase Data Studio 包含一组工具,用于管理,数据建模以及从数据服务器的数据构建查询。EXPLAIN_SQL 例程准备查询并在 XML 中返回查询计划。
如果您计划使用 GBase Data Studio 获得 Visual Explain 输出,您必须为 ONCONFIG 文件中的 SBSPACENAME 配置参数创建并指定缺省 sbspace 名。EXPLAIN_SQL 例程在此 sbspace 中创建 BLOB 对象。
如果使用GBase Data Studio 的信息,请参阅 GBase Data Studio 文档。
UDR 定义例程
UDR 定义例程是内置例程,使用户能够执行各种任务,以开发或修改 GBase 8s 的外部用户定义例程,或者启用 GBase Data Server 驱动程序 JDBC 和 SQL 过程来访问 GBase 8s 和 DB2 数据库通过分布式关系数据库架构(DRDA)协议。
这些是内置 UDR 定义例程:
- ifx_replace_module( )
- ifx_unload_module( )
- jvpcontrol( )
- sqlj.alter_java_path( )
- sqlj.install_jar( )
- sqlj.remove_jar( )
- sqlj.replace_jar( )
- sqlj.setUDTextName( )
- sqlj.unsetUDTextName( )
- sysgbase.Metadata( )
- sysgbase.SQLCAMessage( )
授权使用 UDR 定义例程
如果 IFX_EXTEND_ROLE 配置参数设置为 'On' 或 1,则使用操作共享对象的内置例程的授权仅对数据库服务器管理员和 DBSA 授予 EXTEND 角色的用户可用。缺省情况下启用 IFX_EXTEND_ROLE。
对于不需要此安全功能的数据库,请参阅 GBase 8s 管理员参考手册 中的 IFX_EXTEND_ROLE 的描述,以获取有关 DBSA 如果通过重置来禁用此配置参数的信息。有关将 EXTEND 角色授予单个用户或 PUBLIC 组的语法,请参阅授予 EXTEND 角色主题。
IFX_REPLACE_MODULE 函数
IFX_REPLACE_MODULE 函数将使用 C 语言编写的 UDR 的加载共享对象文件替换为具有不同名称或位置的新版本。如果 IFX_EXTEND_ROLE 配置参数设置为 'On' 或 1,则使用此功能的授权仅对数据库服务器管理员(DBSA)和 DBSA 已授予 EXTEND 角色的用户可用。
IFX_REPLACE_MODULE 函数
![]()
| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| new_module | 要替换 old_module 指定的共享对象文件的新共享对象文件的完整路径名 | 共享对象文件必须与指定的路径名一起存在,其长度不能超过 255 个字节 | 引用字符串 |
| old_module | 要用 new_module 指定共享对象文件替换的共享对象文件的完整路径名 | 共享对象文件必须与指定的路径名一起存在,其长度不能超过 255 个字节 | 引用字符串 |
IFX_REPLACE_MODULE 函数是 DBA 特权函数,它返回的整数值表示共享对象文件替换操作的状态:
- 零(0)表示成功
- 负整数表示错误
不要使用 IFX_REPLACE_MODULE 函数重载相同名称的模块。如果发送到 IFX_REPLACE_MODULE 的旧的和新的模块的全名一样,则会发生预期外的结果。
IFX_REPLACE_MODULE 完成执行后,数据库服务器会老化 old_module 共享对象文件;即,IFX_REPLACE_MODULE 函数之后的所有语句将使用 new_module 共享对象文件中的 UDR,并且当使用它的任何语句完成是,旧模块将会被卸载。因此,在短时间内,old_module 和 new_module 共享对象文件都可以驻留在内存中。如果此老化行为是不受欢迎的,请使用 IFX_UNLOAD_MODULE 函数完全卸载共享对象文件。
在 UNIX™ 上,例如,假设您希望替换 circle.so 共享库,它包含以 C 语言编写的 UDR。如果此库的旧版本驻留在 /usr/apps/opaque_types 目录,新版本在 /usr/apps/shared_libs 目录中,则使用下列 EXECUTE FUNCTION 语句执行 IFX_REPLACE_MODULE 函数:
EXECUTE FUNCTION ifx_replace_module(
"/usr/apps/opaque_types/circle.so",
"/usr/apps/shared_libs/circle.so", "C");
在 Windows™ 上,例如,假设您希望替换 circle.dll 动态链接库,其包含 C UDR。如果此库的旧版本驻留在 C:\usr\apps\opaque_types 目录,新版本在 C:\usr\apps\DLLs 目录,则使用下列 EXECUTE FUNCTION 语句执行 IFX_REPLACE_MODULE 函数:
EXECUTE FUNCTION ifx_replace_module(
"C:\usr\apps\opaque_types\circle.dll",
"C:\usr\apps\DLLs\circle.dll", "C");
要在 GBase 8s ESQL/C 应用程序中执行 IFX_REPLACE_MODULE 函数,您必须将此函数与游标相关联。
有关如何使用 IFX_REPLACE_MODULE 替换共享对象文件的更多信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 中如何设计 UDR 的章节。有关如何使用 IFX_UNLOAD_MODULE 函数的信息,请参阅 IFX_UNLOAD_MODULE 函数 一节。
IFX_UNLOAD_MODULE 函数
IFX_UNLOAD_MODULE 函数从共享内存卸载以 C 语言编写的 UDR 的共享对象文件。
IFX_UNLOAD_MODULE 函数
![]()
| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| module_name | 要卸载文件的完整路径名 | 共享对象文件必须存在并且未被使用。路径名最大长度为 255 字节。 | 引用字符串 |
IFX_UNLOAD_MODULE 函数是所有者特权函数,其所有者是用户 gbasedbt。它返回的整数值表示共享对象文件卸载操作的状态:
- 零(0)表示成功
- 负整数表示错误
IFX_UNLOAD_MODULE 函数只能卸载未使用的共享对象文件;也就是说,当没有执行的 SQL 语句(在任何数据库中)使用指定的共享对象文件中的任何 UDR 时。如果共享对象文件中的任何 UDR 当前正在使用,则 IFX_UNLOAD_MODULE 引发错误。
在 UNIX™ 上,例如,假设您希望卸载 circle.so 共享库,包含 C UDR。如果此库驻留在 /usr/apps/opaque_types 目录,可以使用以下 EXECUTE FUNCTION 语句执行 IFX_UNLOAD_MODULE 函数:
EXECUTE FUNCTION ifx_unload_module
("/usr/apps/opaque_types/circle.so", "C");
在 Windows™ 上,例如,假设希望卸载 circle.dll 动态链接库,包含 C UDR。如果该库在 C:\usr\apps\opaque_types 目录中,您可以使用以下 EXECUTE FUNCTION 语句执行 IFX_UNLOAD_MODULE 函数:
EXECUTE FUNCTION ifx_unload_module
("C:\usr\apps\opaque_types\circle.dll", "C");
有关如何使用 IFX_REPLACE_MODULE( ) 和 IFX_UNLOAD_MODULE( ) UDR 定义例程的更多信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 和 GBase 8s DataBlade API 程序员指南。
jvpcontrol 函数
jvpcontrol( ) 函数是内置迭代函数,可用于获得有关 Java™ 虚拟处理器(JVP)类的信息。
jvpcontrol 函数
![]()
| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| jvp_id | 要搜索信息的 Java™ 虚拟处理器(JVP)类的名称 | 指定的 Java 虚拟处理器类必须存在 | 标识符 |
必须将此函数与 Java 语言的中游标的等效项关联。
使用 MEMORY 关键字
当您指定 MEMORY 关键字时,jvpcontrol 函数返回您指定的 JVP 类的内存使用情况。以下示例请求有关名为 4 的 JVP 类的内存使用情况的信息:
EXECUTE FUNCTION GBASEDBT.JVPCONTROL ("MEMORY 4");
使用 THREADS 关键字
当您指定 THREADS 关键字时,jvpcontrol 函数返回在您指定的 JVP 类上运行的线程的列表。以下示例请求名为 4 的 JVP 类上的运行的线程的信息:
EXECUTE FUNCTION GBASEDBT.JVPCONTROL ("THREADS 4");
有关如何使用 jvpcontrol( ) 和内置 sqlj 例程的信息,请参阅 J/Foundation 开发者指南。
SQLJ Driver 内置过程
使用 SQLJ Driver 内置过程执行以下任务之一:
- 安装、替换或移除一组 Java 类
- 要为包含在 JAR 文件中的 Java 类指定 Java™ 类解析的路径
- 映射或删除用户定义类型与其对应的 Java 类型之间的映射
SQLJ Driver Built-In Procedures
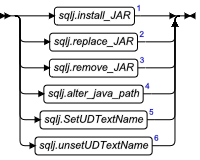
客户端应用程序必须指定 'sqli' 所有者名称以从兼容 ANSI 的数据库中调用这些函数。
SQLJ 内置过程存储在 sysprocedures 系统目录表中。它们被分组到 sqlj 模式下。
对于任何 Java 静态方法,执行的第一个内置过程必须是 sqlj.install_jar( ) 过程。在创建 UDR 或将用户定义数据类型映射到 Java 类之前必须安装 JAR 文件。同样,不能使用任何其它 SQLJ 内置过程直到使用了 sqlj.install_jar( )。
sqlj.install_jar
使用 sqlj.install_jar( ) 过程在当前数据库中安装 JAR 文件,并为它指定一个 JAR 标识符。
sqlj.install_jar

| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| deploy | 导致过程在 JAR 文件中搜寻部署描述符文件的整数 | 无 | 精确数值 |
| jar_file | 包含以 Java 语言编写的 UDR 的 JAR 文件的 URL | URL 的最大长度为 255 字节 | 引用字符串 |
例如,假设 Java™ 类 Chemistry 包含下列静态方法 explosiveReaction( ):
public static int explosiveReaction(int ingredient)
此处的 Chemistry 类驻留在服务器电脑上的这个 JAR 文件中:
/students/data/Courses.jar
您可以使用以下 sqlj.install_jar( ) 过程调用在当前数据库的 Courses.jar 文件中安装所有类:
EXECUTE PROCEDURE
sqlj.install_jar("file://students/data/Courses.jar", "course_jar");
sqlj.install_jar( ) 过程指定 JAR ID,course_jar,分配给它在当前数据库中安装的 Courses.jar 文件。
在数据库中定义 JAR ID 之后,可以在创建和执行以 Java 语言编写的 UDR 使用该 JAR ID。(您必须拥有数据库的 Resource 特权或 DBA 特权,并且还必须具有 Java 语言的 Usage 特权,才能创建或删除 Java UDR。)
当您为第三个参数指定一个非零数字时,数据库服务器将搜索任何包含的部署描述符文件。例如,您可能希望包括包含 SQL 语句的描述符文件,以在 JAR 文件中注册和授予对 UDR 的权限。
如果启用了 IFX_EXTEND_ROLE 配置参数(缺省设置),那么只有 DBSA 或持有 EXTEND 角色的用户可以执行 sqlj.install_jar( ) 过程。当禁用 IFX_EXTEND_ROLE 时,任何用户都可以执行 sqlj.install_jar( )。
Jar 文件的文件权限
sqlj.install_jar( ) 在数据库中安装 JAR 文件之后,为此文件声明一个 JAR ID。 GBase 8s 只有在安装了 GBase 8s 实例的用户(通常为用户 gbasedbt)具有读取该文件的权限的情况下才能访问该 JAR 文件的 JAR 文件所在的目录。例如,在 UNIX™ 系统上,这意味着尝试读取具有600 个权限的 JAR 文件失败,并显示 FILENOTFOUND 异常。然而,在 chmod 实用程序将权限设置为 660(rw-rw----)后,相同的操作会成功。
您必须拥有数据库的 Resource 特权或 DBA 特权,并且还必须具有 Java 语言的 Usage 特权,才能创建或删除 Java UDR。
sqlj.replace_jar
使用 sqlj.replace_jar( ) 过程将先前安装的 JAR 文件替换为新版本。使用此语法时,您只需提供新的 JAR 文件,并为其指定要替换的文件的 JAR ID。
sqlj.replace_jar
![]()
| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| jar_file | 包含以 Java 语言编写的 UDR 的 JAR 文件的 URL | URL 的最大长度是 255 字节。 | 引用字符串 |
如果尝试替换由一个或多个 UDR 引用的 JAR 文件,那么数据库服务器会生成错误。在替换 JAR 文件之前,您必须删除引用的 UDR。
例如,以下调用将以前为 course_jar 标识符安装的 Courses.jar 文件替换为 Subjects.jar 文件:
EXECUTE PROCEDURE
sqlj.replace_jar("file://students/data/Subjects.jar", "course_jar");
在替换 Course.jar 文件之前,必须使用 DROP FUNCTION(或 DROP ROUTINE)语句删除用户定义的函数 sql_explosive_reaction( )。(您必须拥有数据库的 Resource 特权或 DBA 特权,并且还必须具有 Java 语言的 Usage 特权,才能创建或删除 Java UDR。)
如果启用了 IFX_EXTEND_ROLE 配置参数(缺省设置),那么只有 DBSA 或持有 EXTEND 角色的用户可以执行 sqlj.replace_jar( ) 过程。当禁用 IFX_EXTEND_ROLE 时,任何用户都可以执行 sqlj.replace_jar( )。
sqlj.remove_jar
使用 sqlj.remove_jar( ) 过程从当前数据库移除先前安装的 JAR 文件。您必须拥有数据库的 Resource 特权或 DBA 特权,并且还必须具有 Java 语言的 Usage 特权,才能创建或删除 Java UDR。
sqlj.remove_jar

| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| deploy | 导致过程在 JAR 文件中搜寻部署描述符文件的整数 | 无 | 精确数值 |
当尝试移除被一个或多个 UDR 引用的 JAR 文件时,数据库服务器生成 46003 错误。您必须在替换此 JAR 文件前删除引用的 UDR。 非法 JAR 文件名称生成 46002 错误。
例如,下列 SQL 语句移除与 course_jar JAR ID 相关联的 JAR 文件:
DROP FUNCTION sql_explosive_reaction;
EXECUTE PROCEDURE sqlj.remove_jar("course_jar");
当您为第二个参数指定非零数字时,数据库服务器将搜索任何包含的部署描述符文件。例如,您可能希望包括包含 SQL 语句的描述符文件以撤销关联的 JAR 文件中的 UDR 特权,并从数据库中删除它们。
如果启用 IFX_EXTEND_ROLE 配置参数(缺省设置),那么只有 DBSA 或持有 EXTEND 角色的用户可以执行 sqlj.remove_jar( ) 过程。当禁用 IFX_EXTEND_ROLE 时,任何用户都可以执行 sqlj.remove_jar( )。
sqlj.alter_java_path
使用 sqlj.alter_java_path( ) 指定当例程管理器解析用 Java 语言编写的 UDR 的 JAR 文件的相关的 Java 类时使用 jar 文件路径。
sqlj.alter_java_path

| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| class_id | 包含实现 UDR 的方法的 Java™ 类 | Java 必须在 jar_id 指定的 JAR 文件中存在。标识符不能超过 255 个字节。 | 特定于语言 |
| package_id | 包含 Java 类的包的名称 | package_id.class_id 的完整限定标识符不能超过 255 个字符 | 特定于语言 |
您指定的 JAR ID (即要更改 JAR 文件路径的 JAR 标识和 JAR ID 的解析)必须都已使用 sqlj.install_jar 过程安装过。当调用使用 Java 语言编写的 UDR 时,例程管理器尝试加载 UDR 驻留的 Java 类。此时,它必须解析此 Java 类对其它 Java 类所做的引用。
这些类引用的三种类型是:
- 引用 JVPCLASSPATH 配置参数指定的 Java 类(例如 java.util.Vector 的 Java 系统类)
- 引用与 UDR 位于同一 JAR 文件中的类
- 引用包含 UDR 的 JAR 文件之外的类。
例程管理隐式解析之前列表中的类型 1 和类型 2。要解析类型 3 的引用,它检查 JAR 文件路径中所有最近调用 sqlj.alter_java_path( ) 指定的 JAR 文件。
如果例程管理器不能解析类引用,它会发出异常。例程管理器在执行类型 1 和类型 2 解析之后检查 JAR 文件路径以进行类引用。
如果希望从 JAR 文件路径指定的 JAR 文件加载 Java™ 类,请确保 Java 类不存在于 JVPCLASSPATH 配置参数中。否则,系统装入程序会首先采用此 Java 类,这可能导致加载不是您期望的类。
假设 sqlj.install_jar( ) 过程和 CREATE FUNCTION 已经如前面部分所述的执行。以下 SQL 语句调用 course_jar JAR 文件中的 sql_explosive_reaction( ) 函数:
EXECUTE PROCEDURE alter_java_path("course_jar", "(professor/*, prof_jar)");
EXECUTE FUNCTION sql_explosive_reaction(10000);
例程管理器尝试加载 Chemistry 类。它使用调用 sqlj.alter_java_path( ) 指定的路径来解析任何类引用。因此,它检查 prof_jar 标识的 JAR 文件的 professor 包中的类。
如果启用了 IFX_EXTEND_ROLE 配置参数(缺省设置),那么只有 DBSA 或持有 EXTEND 角色的用户可以执行 sqlj.alter_java_path( ) 过程。当 IFX_EXTEND_ROLE 被禁用时,任何用户都可以执行 sqlj.alter_java_path( )。(但是不管 IFX_EXTEND_ROLE 如何设置,您必须拥有数据库的 Resource 特权或 DBA 特权,并且还必须拥有 Java 语言的 Usage 特权,才能创建或删除 Java UDR。)
sqlj.setUDTextName
使用 sqlj.setUDTextName( ) 过程定义用户定义的数据类型和 Java 类之间的映射。
sqlj.SetUDTextName

| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| class_id | 包含 Java 数据类型的 Java 类 | 限定名称 package_id.class_id 不能超过 255 个字节 | Java 标识符的特定于语言的规则 |
| data_type | 要创建映射的用户定义的类型 | 名称不能超过 255 个字节 | 标识符 |
| package_id | 包含 class_id Java 类的包的名称 | 与 class_id 的限制相同 | Java 标识符的特定于语言的规则 |
必须已经在 CREATE DISTINCT TYPE 、CREATE OPAQUE TYPE 或 CREATE ROW TYPE 语句中注册此用户定义的数据类型。
要查找用户定义数据类型的 Java 类,数据库服务器将在 JAR 文件路径中搜索,该路径由 sqlj.alter_java_path( ) 过程指定,有关 JAR 文件路径的更多信息,请参阅 sqlj.alter_java_path。
SQLJ 驱动程序查找 CLASSPATH 在客户端环境中指定的路径,然后向数据库服务器询问 Java 类的名称。
setUDTextName( ) 例程是使用 Java 编程语言规范的 SQLJ:SQL 例程的扩展。
如果启用了 IFX_EXTEND_ROLE 配置参数(缺省设置),那么只有 DBSA 或持有 EXTEND 角色的用户可以执行 setUDTextName( ) 过程。当 IFX_EXTEND_ROLE 被禁用时,任何用户都可以执行 setUDTextName( )。(但是不管 IFX_EXTEND_ROLE 如何设置,您必须拥有数据库的 Resource 特权或 DBA 特权,并且还必须拥有 Java 语言的 Usage 特权,才能创建或删除 Java™ UDR。)
sqlj.unsetUDTextName
使用 sqlj.unsetUDTextName( ) 例程移除用户定义数据类型到 Java 类的映射。
sqlj.unsetUDTextName
![]()
| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| data_type | 要移除映射的用户定义的数据类型 | 必须存在 | 标识符 |
此例程删除 SQL 到 Java 的映射,从而从数据库服务器的共享内存中删除 Java 类的任何缓存副本。
unsetUDTextName( ) 例程是使用 Java 编程语言规范的 SQLJ:SQL 例程的扩展。
如果启用了 IFX_EXTEND_ROLE 配置参数(缺省设置),那么只有 DBSA 或持有 EXTEND 角色的用户可以执行 unsetUDTextName( ) 过程。当 IFX_EXTEND_ROLE 被禁用时,任何用户都可以执行 unsetUDTextName( )。(但是不管 IFX_EXTEND_ROLE 如何设置,您必须拥有数据库的 Resource 特权或 DBA 特权,并且还必须拥有 Java 语言的 Usage 特权,才能创建或删除 Java™ UDR。)
DRDA 支持函数
当 GBase 8s 实例配置为 DRDA 应用程序服务器时, GBase 8s 提供支持分布式关系数据库架构(DRDA)协议的内置函数。(这通过在配置文件中将 DBSERVERALIASES 设置为 DRDA 来实现。)
- sysgbase.Metadata 函数向驱动程序为 JDBC 和 SQL 客户端应用程序提供数据库元数据信息。
- sysgbase.SCLCAMessage 函数支持 DRDA 错误处理。
这些函数的 GBase 8s 实现符合 DR Level 5 SQLAM 7 标准。
Metadata 函数
sysgbase.Metadata 函数是一个 SPL 例程,它可由 GBase Data Server 驱动程序调用,以便 JDBC 和 SQL 应用程序动态检索数据库元数据。Metadata 例程在配置为 DRDA 应用程序服务器的 GBase 8s 实例的每个数据库中自动创建,客户端应用程序必须指定 'sysgbase' 为所有者名称以从符合 ANSI 的数据库调用此函数。
它具有以下常规定义:
create procedure sysgbase.METADATA() returning
integer as allProceduresAreCallable,
integer as allTablesAreSelectable,
integer as nullsAreSortedHigh,
integer as nullsAreSortedLow,
integer as nullsAreSortedAtStart,
integer as nullsAreSortedAtEnd,
integer as usesLocalFiles,
integer as usesLocalFilePerTable,
integer as storesUpperCaseIdentifiers,
integer as storesLowerCaseIdentifiers,
integer as storesMixedCaseIdentifiers,
integer as storesLowerCaseQuotedIdentifiers,
integer as storesMixedCaseQuotedIdentifiers,
lvarchar(4096) as getSQLKeywords,
varchar(100) as getNumericFunctions,
varchar(100) as getStringFunctions,
varchar(100) as getSystemFunctions,
varchar(100) as getTimeDateFunctions,
varchar(25) as getSearchStringEscape,
varchar(25) as getExtraNameCharacters,
integer as supportsAlterTableWithAddColumn,
integer as supportsAlterTableWithDropColumn,
integer as supportsConvert,
varchar(255) as supportsConvertType,
integer as supportsDifferentTableCorrelationNames,
integer as supportsExpressionsInOrderBy,
integer as supportsOrderByUnrelated,
integer as supportsGroupBy,
integer as supportsGroupByUnrelated,
integer as supportsGroupByBeyondSelect,
integer as supportsMultipleResultSets,
integer as supportsMultipleTransactions,
integer as supportsCoreSQLGrammar,
integer as supportsExtendedSQLGrammar,
integer as supportsANSI92IntermediateSQL,
integer as supportsANSI92FullSQL,
integer as supportsIntegrityEnhancementFacility,
integer as supportsOuterJoins,
integer as supportsFullOuterJoins,
integer as supportsLimitedOuterJoins,
varchar(50) as getSchemaTerm,
varchar(50) as getProcedureTerm,
varchar(50) as getCatalogTerm,
integer as isCatalogAtStart,
varchar(50) as getCatalogSeparator,
integer as supportsSchemasInDataManipulation,
integer as supportsSchemasInProcedureCalls,
integer as supportsSchemasInTableDefinitions,
integer as supportsSchemasInIndexDefinitions,
integer as supportsSchemasInPrivilegeDefinitions,
integer as supportsCatalogsInDataManipulation,
integer as supportsCatalogsInProcedureCalls,
integer as supportsCatalogsInTableDefinitions,
integer as supportsCatalogsInIndexDefinitions,
integer as supportsCatalogsInPrivilegeDefinitions,
integer as supportsPositionedDelete,
integer as supportsPositionedUpdate,
integer as supportsSelectForUpdate,
integer as supportsStoredProcedures,
integer as supportsSubqueriesInComparisons,
integer as supportsUnion,
integer as supportsUnionAll,
integer as supportsOpenCursorsAcrossCommit,
integer as supportsOpenCursorsAcrossRollback,
integer as supportsOpenStatementsAcrossCommit,
integer as supportsOpenStatementsAcrossRollback,
integer as getMaxBinaryLiteralLength,
integer as getMaxCharLiteralLength,
integer as getMaxColumnNameLength,
integer as getMaxColumnsInGroupBy,
integer as getMaxColumnsInIndex,
integer as getMaxColumnsInOrderBy,
integer as getMaxColumnsInSelect,
integer as getMaxColumnsInTable,
integer as getMaxConnections,
integer as getMaxCursorNameLength,
integer as getMaxIndexLength,
integer as getMaxSchemaNameLength,
integer as getMaxProcedureNameLength,
integer as getMaxCatalogNameLength,
integer as getMaxRowSize,
integer as doesMaxRowSizeIncludeBlobs,
integer as getMaxStatementLength,
integer as getMaxStatements,
integer as getMaxTableNameLength,
integer as getMaxTablesInSelect,
integer as getMaxUserNameLength,
integer as getDefaultTransactionIsolation,
integer as supportsTransactions,
varchar(50) as supportsTransactionIsolationLevel,
integer as supportsDataDefinitionAndDataManipulationTransactions,
integer as supportsDataManipulationTransactionsOnly,
integer as dataDefinitionCausesTransactionCommit,
integer as dataDefinitionIgnoredInTransactions,
varchar(100) as supportsResultSetType,
varchar(100) as supportsResultSetConcurrency,
varchar(100) as ownUpdatesAreVisible,
varchar(100) as ownDeletesAreVisible,
varchar(100) as ownInsertsAreVisible,
varchar(100) as othersUpdatesAreVisible,
varchar(100) as othersDeletesAreVisible,
varchar(100) as othersInsertsAreVisible,
varchar(100) as updatesAreDetected,
varchar(100) as deletesAreDetected,
varchar(100) as insertsAreDetected,
integer as supportsBatchUpdates,
integer as supportsSavepoints,
integer as supportsGetGeneratedKeys
sysgbase.SQLCAMessage 函数
缺省情况下,用于 JDBC 的 GBase Data Server Driver 和用于 GBase 8s 的 SQL 不返回本地化错误消息。但是当在连接 URL 中设置 "retrieveMessagesFromServerOnGetMessage=true" 属性时,需要来自服务器的详细和本地化的错误消息。
SQLCAMessage 函数是一个 SPL 例程,支持从远程 DB2 或 GBase 8s 数据库服务器到使用分布式关系数据库架构(DRDA)协议的客户端应用程序检索详细的错误消息文本。在配置为 DRDA 应用程序服务器的 GBase 8s 实例的每个数据库中自动创建 SQLCAMessage 例程。用于 JDBC 和 SQL 客户端应用程序 GBase Data Server 驱动程序必须指 'sysgbase' 所有者名称,以从符合 ANSI 的数据库调用此函数。
SQLCAMessage 函数基于 SQL 通信区域(SQLCA)中的 SQLSTATE 代码检索本地化的错误消息。
此函数的定义使用 IN 、OUT 和 INOUT 参数:
CREATE function sysgbase.SQLCAMessage (
IN SQLCode INTEGER,
IN SQLErrml SMALLINT,
IN SQLErrmc VARCHAR(70),
IN SQLErrp CHAR(8),
IN SQLErrd0 INTEGER,
IN SQLErrd1 INTEGER,
IN SQLErrd2 INTEGER,
IN SQLErrd3 INTEGER,
IN SQLErrd4 INTEGER,
IN SQLErrd5 INTEGER,
IN SQLWarn CHAR(11),
IN SQLState CHAR(5),
IN MessageFileName VARCHAR(20),
INOUT Locale VARCHAR(33),
OUT Message LVARCHAR(4096),
OUT Rcode INTEGER)
RETURNING INTEGER
EXTERNAL NAME '(SQLCAMessage)'
LANGUAGE C
要调用此函数,可以使用此语法:
sysgbase.SQLCAMessage
![]()
| 参数 | 描述 | 限制 | 语法 |
|---|---|---|---|
| error_number | 错误的 SQLCODE 值 | 必须存在 | 表达式 |
| input_locale | 接收消息的输入语言环境的名称。缺省为 U.S. English 语言环境(en_us) | 必须存在 | 标识符 |
| message_file | 消息文件的名称 | 必须存在 | 路径名 |
该函数从指定的 SQLCODE 和 input_locale 的指定 message_file 检索文本。返回的代码表示调用执行 SQLCAMessage 例程成功或失败。
GBase 8s DRDA 应用程序试图使用指定的输出参数检索错误消息文本:
- SQLCODE
- input_locale 和
- message_file
GBase 8s DRDA 应用程序试图使用指定的输出参数检索错误消息文本:如果 MessageFileName 参数 message_file 为 NULL ,则使用缺省的消息文件(errmsgtxt)。如果使用指定的 input_locale 检索失败,则使用缺省语言环境(en_us)来检索错误消息。如果适用,令牌数组用于替换检索的消息文本中的标记。
如果检索成功,
- SQLCODE 从错误消息中移除,
- 错误消息复制到 OUT 参数 'Message'
- 用于检索消息的区域设置将复制到 INOUT 参数 'Locale'。
如果检索失败,则错误消息文本 "Message not found" 将出现在 Message 参数中。
对于这两种情况,OUT 参数 Rcod 设置为执行此 SPL 例程的返回码。
ISAM 错误的详细信息从 SQLERRD[0] 值提供。ISAM 错误消息连接到实际的错误消息字符串并返回到应用程序。
对于 SQLCAMessage 函数可以返回相应错误消息文本的 SQLSTATE 值的代码,请参阅 SQLSTATE 代码列表。
SQL 包扩展
SQL 包扩展提供可在与 GBase 8s 以外的数据库服务器兼容的应用程序中使用的 SPL 例程。SQL 包扩展是内置扩展。
SQL 包扩展中包括以下模块:
- DBMS_ALERT
- DBMS_LOB
- DBMS_OUTPUT
- DBMS_RANDOM
- UTL_FILE
- UTL_RAW
- ODCICONST
- UTL_ENCODE
- DBMS_CRYPTO
DBMS_ALERT 包
DBMS_ALERT 包提供一组用于注册警报、发送警报和接收警报的过程。注册包时,警报会存储在数据库中创建的 DBMS_ALERT_EVENTS、DBMS_ALERT_REGISTERED 和 DBMS_ALERT_SIGNALED 表中。当您想要针对特定事件发送警报时,DBMS_ALERT 包中的过程十分有用。例如,您可能想要在因为一个或多个表发生更改而导致触发器激活时发送警报。
DBMS_ALERT 包具有以下系统定义的例程。
REGISTER 过程
REGISTER 过程注册当前会话以接收指定的警报。
语法
>>-DBMS_ALERT.REGISTER--(--name--)-----------------------------><
过程参数
name
类型为 VARCHAR(128) 的输入参数,用于指定警报的名称。
REMOVE 过程
REMOVE 过程从当前会话中除去对指定警报的注册。
语法
>>-DBMS_ALERT.REMOVE--(--name--)-------------------------------><
过程参数
name
类型为 VARCHAR(128) 的输入参数,用于指定警报的名称。
REMOVEALL 过程
REMOVEALL 过程从当前会话中除去对所有警报的注册。
语法
>>-DBMS_ALERT.REMOVEALL----------------------------------------><
SET_DEFAULTS
SET_DEFAULTS 过程设置 WAITONE 和 WAITANY 过程使用的轮询时间间隔。
语法
>>-DBMS_ALERT.SET_DEFAULTS--(--sensitivity--)------------------><
过程参数
sensitivity
类型为 INTEGER 的输入参数,用于指定 WAITONE 和 WAITANY 过程检查信号的时间间隔(以秒为单位)。如果未指定值,那么缺省情况下时间间隔为 1 秒。
SIGNAL 过程
SIGNAL 过程在指定的警报出现时发出信号。信号包括随警报传递的消息。发出 SIGNAL 调用时,该消息将分发至侦听器(针对警报注册的进程)。
语法
>>-DBMS_ALERT.SIGNAL--(--name--,--message--)-------------------><
过程参数
name
类型为 VARCHAR(128) 的输入参数,用于指定警报的名称。
message
类型为 VARCHAR(32672) 的输入参数,用于指定随此警报传递的信息。发生警报时,WAITANY 或 WAITONE 过程可返回此消息。
WAITANY 过程
WAITANY 过程等待任何已注册的警报出现。
语法
>>-DBMS_ALERT.WAITANY--(--name--,--message--,--status--,--timeout--)-><
过程参数
name
类型为 VARCHAR(128) 的输出参数,其中包含警报的名称。
message
类型为 VARCHAR(32672) 的输出参数,其中包含 SIGNAL 过程发送的消息。
status
类型为 INTEGER 的输出参数,其中包含过程返回的状态码。可能为以下值:
0
发生了警报。
1
发生了超时。
timeout
类型为 INTEGER 的输入参数,用于指定等待警报的时间量(以秒为单位)。
WAITONE 过程
WAITONE 过程等待指定的警报出现。
语法
>>-DBMS_ALERT.WAITONE--(--name--,--message--,--status--,--timeout--)-><
过程参数
name
类型为 VARCHAR(128) 的输入参数,用于指定警报的名称。
message
类型为 VARCHAR(32672) 的输出参数,其中包含 SIGNAL 过程发送的消息。
status
类型为 INTEGER 的输出参数,其中包含过程返回的状态码。可能为以下值:
0
发生了警报。
1
发生了超时。
timeout
类型为 INTEGER 的输入参数,用于指定等待所指定警报的时间量(以秒为单位)。
DBMS_LOB包
DBMS_LOB包用来在PLSQL中操作BLOB,CLOB类型。包中提供了以下操作方法。
APPEND过程
将指定长度的源LOB数据追加到目标LOB中。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dest_lob | 目标大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。该参数以IN、OUT的方式传入,在使用时需要变量接收。 | 表达式 |
| src_lob | 源大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
例如:将clob类型数据b追加给clob类型数据a。
declare
a clob;
b clob;
begin
a:='WWW';
b:='ooo';
dbms_lob.append(a,b);
dbms_output.put_line(a);
> end;
> /
PL/SQL procedure successfully completed.
WWWooo
WRITEAPPEND过程
追加指定长度字符的数据到LOB对象的末尾。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dest_lob | 目标大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| amount | 追加数据的长度 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节长度,CLOB为字符长度。 | 精确数值 |
| buffer | 待追加的数据 | 为LVARCHAR类型或能通过隐式类型转换为LVARCHAR类型的表达式。 | 表达式 |
例如:给clob类型a追加字符串bbb
declare
a clob;
amount int;
b varchar(200);
begin
a:=empty_clob();
b:='bbb';
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a,length(b),b);
dbms_output.put_line(a);
end;
> /
PL/SQL procedure successfully completed.
bbb
COMPARE过程
比较两个LOB的数据,返回一个INTEGER类型。返回0表示相等。-1表示LOB_1<LOB_2。1表示LOB_1>LOB_2。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_1 | 大对象1 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| lob_2 | 大对象2 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| amount | 要比较的总长度 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认2147483647。 | 精确数值 |
| offset_1 | 第一个临时大对象起始偏移 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认1。 | 精确数值 |
| offset_2 | 第二个临时大对象起始偏移 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认1。 | 精确数值 |
例如:比较a跟a1的结果
declare
a clob;
a1 clob;
amount int;
b varchar(200);
comar int;
begin
a:=empty_clob();
a1:=empty_clob();
b:='bbb';
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a,length(b),b);
dbms_lob.createtemporary(a1,true);
dbms_lob.open(a1,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a1,length(b),b);
comar:=dbms_lob.compare(a,a1,20,1,1);
dbms_output.put_line('a:'||a);
dbms_output.put_line('a1:'||a1);
dbms_output.put_line(comar);
end;
> /
PL/SQL procedure successfully completed.
a:bbb
a1:bbb
0
OPEN过程
打开一个LOB对象。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| open_mode | 打开方式 | 支持LOB_READONLY(只读),LOB_READWRITE(读写)两种打开模式。 | 固定写法 |
例如:以读写模式打开大对象a。
declare
a clob;
amount int;
b varchar(200);
begin
a:=empty_clob();
b:='bbb';
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a,length(b),b);
dbms_output.put_line(a);
end;
> /
PL/SQL procedure successfully completed.
bbb
CLOSE过程
关闭一个之前打开的LOB对象。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
例如:先打开大对象a,然后操作完成后关闭大对象a。
declare
a clob;
amount int;
b varchar(200);
begin
a:=empty_clob();
b:='bbb';
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a,length(b),b);
dbms_output.put_line(a);
dbms_lob.close(a);
end;
> /
PL/SQL procedure successfully completed.
bbb
COPY过程
将指定长度的源LOB数据插入到目标LOB中。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dest_lob | 目标大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| src_lob | 源大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| amount | 要比较的总长度 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符。 | 精确数值 |
| dest_offset | 目标大对象的起始偏移 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认1。 | 精确数值 |
| src_offset | 源大对象起始偏移 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认1。 | 精确数值 |
例如:将a1大对象1位后的部分插入到a大对象1位后,并且复制1次。
declare
a clob;
a1 clob;
amount int;
b varchar(200);
b1 varchar(200);
comar int;
begin
a:=empty_clob();
a1:=empty_clob();
b:='bbb';
b1:='aaa';
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a,length(b),b);
dbms_lob.createtemporary(a1,true);
dbms_lob.open(a1,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a1,length(b1),b1);
dbms_output.put_line('a:'||a);
dbms_output.put_line('a1:'||a1);
dbms_lob.copy(a,a1,1,1,1);
dbms_output.put_line('a:'||a);
dbms_output.put_line('a1:'||a1);
dbms_output.put_line(comar);
end;
/
PL/SQL procedure successfully completed.
a:bbb
a1:aaa
a:abb
a1:aaa
>
ERASE过程
擦除指定偏移开始的指定长度LOB数据。BLOB用0,CLOB用空格代替原有数据。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| amount | 需要擦除数据的总数 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符。AMOUNT<0将报错,AMOUNT大于原字段长度,将擦除所有数据。 | 精确数值 |
| offset | 起始偏移 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认1。 | 精确数值 |
例如:擦除大对象a的前2位。
declare
a clob;
b varchar2(20);
amount int;
begin
a:=empty_clob();
b:='bbbb';
amount:=2;
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a,length(b),b);
dbms_output.put_line(a);
dbms_lob.erase(a,amount,1);
dbms_output.put_line(a);
end;
/
PL/SQL procedure successfully completed.
bbbb
bb
GETLENGTH过程
返回LOB数据的长度。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
例如:计算大对象a的长度。
declare
a clob;
b varchar2(20);
amount int;
len int;
begin
a:=empty_clob();
b:='bbbb';
amount:=10;
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a,length(b),b);
len := dbms_lob.getlength(a);
dbms_output.put_line(len);
end;
/
PL/SQL procedure successfully completed.
4
SUBSTR过程
截取指定偏移的字符串。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| amount | 读取的数据长度 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认32739,上限32739,实际获取为大对象长度与AMOUNT的小值。。 | 精确数值 |
| offset | 起始偏移 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认1。 | 精确数值 |
例如:截取大对象a的前两位,从第一位开始。
declare
a clob;
b varchar2(20);
amount int;
sub varchar2(20);
begin
a:=empty_clob();
b:='bbbb';
amount:=2;
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITEAPPEND(a,length(b),b);
sub := dbms_lob.substr(a,amount,1);
dbms_output.put_line(sub);
end;
/
PL/SQL procedure successfully completed.
bb
READ过程
读取指定偏移开始的指定长度数据到buffer中。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| amount | 读取数据的总数 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符。IN\OUT方式传入,需要声明变量接收。 | 精确数值 |
| offset | 起始偏移 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认1。 | 精确数值 |
| buffer | 存储数据的缓存区 | 为LVARCHAR类型或能通过隐式类型转换为LVARCHAR类型的表达式。OUT方式输出,需要声明变量接收。 | 表达式 |
例如:读取大对象a的值
declare
a clob;
b varchar2(20);
buffer varchar2(20);
amount int;
begin
a:=empty_clob();
b:='bbbb';
amount:=2;
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITE(a,length(b),1,b);
dbms_lob.read(a,amount,1,buffer);
dbms_output.put_line(buffer);
end;
/
PL/SQL procedure successfully completed.
bb
WRITE过程
写入指定长度字符的数据到LOB对象,从LOB对象的指定绝对偏移开始。如果指定的位置有数据,则新写的会覆盖原来的数据。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| amount | 写入的数据总数 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符。IN\OUT方式传入,需要声明变量接收。 | 精确数值 |
| offset | 起始偏移 | 数值类型或者能通过隐式转换为数值类型的表达式,BLOB为字节,CLOB为字符,默认1。 | 精确数值 |
| buffer | 存储数据的缓存区 | 为LVARCHAR类型或能通过隐式类型转换为LVARCHAR类型的表达式。 | 表达式 |
例如:向大对象a中写入数据
declare
a clob;
b varchar2(20);
amount int;
begin
a:=empty_clob();
b:='bbbb';
amount:=2;
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITE(a,length(b),1,b);
dbms_output.put_line(a);
end;
/
PL/SQL procedure successfully completed.
bbbb
CREATETEMPORARY过程
创建一个临时的LOB对象,并存储在临时的表空间里。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
| cache | 缓存 | 只支持true。代表是否将lob读到缓存里。 | 固定写法 |
| dur | 存活周期 | 只支持DBMS_LOB.SESSION和DBMS_LOB.CALL。DBMS_LOB.SESSION表示会话结束释放空间。DBMS_LOB.CALL表示调用结束释放空间。 | 固定写法 |
例如:创建临时大对象a
declare
a clob;
b varchar2(20);
buffer varchar2(20);
amount int;
begin
a:=empty_clob();
b:='bbbb';
amount:=2;
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITE(a,length(b),1,b);
dbms_lob.read(a,amount,1,buffer);
dbms_output.put_line(buffer);
end;
/
FREETEMPORARY过程
释放临时的LOB操作符。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| lob_loc | 大对象 | 为CLOB类型或能通过隐式类型转换为CLOB类型的表达式。也可以是BLOB类型或能通过隐式类型转换为BLOB类型的表达式,其他数据类型报错。 | 表达式 |
例如:释放临时大对象a
declare
a clob;
b varchar2(20);
buffer varchar2(20);
amount int;
begin
a:=empty_clob();
b:='bbbb';
amount:=2;
dbms_lob.createtemporary(a,true);
dbms_lob.open(a,dbms_lob.lob_readwrite);
dbms_lob.WRITE(a,length(b),1,b);
dbms_lob.read(a,amount,1,buffer);
dbms_output.put_line(buffer);
dbms_lob.freetemporary(a);
end;
/
PL/SQL procedure successfully completed.
bb
DBMS_OUTPUT 包
DBMS_OUTPUT 包提供一组用于将消息(文本行)放到消息缓冲区中以及从消息缓冲区获取消息的过程。在应用程序调试期间,当您需要将消息写入标准输出时,这些过程十分有用。使用命令行处理器 (CLP) 命令 SET SERVEROUTPUT ON 将输出重定向至标准输出。自主过程内不支持 DISABLE 和 ENABLE 过程。自主过程是这样一个过程:调用时,它在新事务中以独立于原始事务的方式执行。
DISABLE 过程
DISABLE 过程禁用消息缓冲区。此过程运行后,将废弃消息缓冲区中的所有消息。对 PUT、PUT_LINE 或 NEW_LINE 过程的调用会被忽略,并且不会向发送方返回任何错误。
语法
>> -DBMS_OUTPUT.DISABLE-----------------------------------------><
ENABLE 过程
ENABLE 过程启用消息缓冲区。进行单个会话期间,应用程序可将消息放到消息缓冲区中以及从消息缓冲区获取消息。
语法
>>-DBMS_OUTPUT.ENABLE--(--buffer_size--)-----------------------><
过程参数
buffer_size
类型为 INTEGER 的输入参数,用于指定消息缓冲区的最大长度(以字节为单位)。如果对 buffer_size 指定小于 2000 的值,那么缓冲区大小将设置为 2000。如果该值为 NULL,那么缺省缓冲区大小为 20000。
GET_LINE 过程
GET_LINE 过程从消息缓冲区获取文本行。该文本必须以行结束字符序列终止。
语法
>>-DBMS_OUTPUT.GET_LINE--(--line--,--status--)-----------------><
过程参数
line
类型为 VARCHAR(32672) 的输出参数,用于从消息缓冲区返回文本行。
status
类型为 INTEGER 的输出参数,用于指示是否从消息缓冲区返回了行:
0 指示已返回行
1 指示未返回行
GET_LINES 过程
GET_LINES 过程从消息缓冲区获取一行或多行文本并将该文本存储在集合中。该文本的每行必须以行结束字符序列终止。
语法
>>-DBMS_OUTPUT.GET_LINES--(--lines--,--numlines--)-------------><
过程参数
lines
类型为 DBMS_OUTPUT.CHARARR 的输出参数,用于从消息缓冲区返回文本行。类型 DBMS_OUTPUT.CHARARR 在内部定义为 VARCHAR(32672) ARRAY[2147483647] 数组。
numlines
类型为 INTEGER 的输入和输出参数。用作输入时,指定要从消息缓冲区检索的行数。用作输出时,指示从消息缓冲区检索到的实际行数。如果 numlines 的输出值小于输入值,那么消息缓冲区中没有其他行。
NEW_LINE 过程
NEW_LINE 过程将行结束字符序列放到消息缓冲区中。
语法
>>-DBMS_OUTPUT.NEW_LINE----------------------------------------><
PUT 过程
PUT 过程将字符串放到消息缓冲区中。字符串结尾不会写入任何行结束字符序列。
语法
>>-DBMS_OUTPUT.PUT--(--item--)---------------------------------><
过程参数
item
类型为 VARCHAR(32672) 的输入参数,用于指定要写入消息缓冲区的文本。
PUT_LINE 过程
PUT_LINE 过程将包括行结束字符序列的单行放到消息缓冲区中。
语法
>>-DBMS_OUTPUT.PUT_LINE--(--item--)----------------------------><
过程参数
item
类型为 VARCHAR(32672) 的输入参数,用于指定要写入消息缓冲区的文本。
DBMS_RANDOM 包
DBMS_RANDOM 包提供生成随机数的机制。使用 INITIALIZE 过程可设置种子值,随机数生成器使用该值来生成数目。重复足够次数后,生成的一些值可能重复。要降低值重复的可能性,请使用 SEED 过程定期更改种子值。
INITIALIZE 过程
INITIALIZE 过程使用指定的整数种子值初始化系统包且该过程为可选。
语法
>>-DBMS_RANDOM_INITIALIZE ()-----------------------------------><
此示例:
execute procedure dbms_random_initialize (17809465);
返回此输出:
Routine executed.
SEED 过程
SEED 过程使用指定的整数值重置种子值。
语法
>>-DBMS_RANDOM_SEED ()-----------------------------------------><
此示例:
execute procedure dbms_random_seed (-45902345);
返回此输出:
Routine executed.
RANDOM 函数
RANDOM 函数使用种子值返回随机整数。
语法
>>-DBMS_RANDOM_RANDOM ()---------------------------------------><
此示例:
insert into random_test VALUES (0, dbms_random_random());
返回此输出:
1 row(s) inserted.
TERMINATE 过程
TERMINATE 过程通过将种子值重置为 0 终止使用系统包且该过程为可选。
语法
>>-DBMS_RANDOM_TERMINATE ()------------------------------------><
此示例:
execute procedure dbms_random_terminate ();
返回此输出:
Routine executed.
UTL_FILE 包
UTL_FILE 包提供一组用于读取以及写入数据库服务器文件系统上的文件的例程。
FCLOSE 过程
FCLOSE 过程关闭指定的文件。
语法
>>-UTL_FILE.FCLOSE--(--file--)---------------------------------><
过程参数
file
类型为 UTL_FILE.FILE_TYPE 的输入或输出参数,其中包含文件句柄。文件关闭时,此值设置为 0。
FCLOSE_ALL 过程
FCLOSE_ALL 过程关闭所有打开的文件。即使没有打开的文件要关闭,该过程也会成功运行。
语法
>>-UTL_FILE.FCLOSE_ALL-----------------------------------------><
FFLUSH 过程
FFLUSH 过程将写入缓冲区中未写入的数据强制写入文件。
语法
>>-UTL_FILE.FFLUSH--(--file--)---------------------------------><
过程参数
file
类型为 UTL_FILE.FILE_TYPE 的输入参数,其中包含文件句柄。
FOPEN 函数
FOPEN 函数打开文件以执行 I/O。
语法
>>-UTL_FILE.FOPEN--(--location--,--filename--,--open_mode--+-----------------+--)-><
'-,--max_linesize-'
返回值
此函数返回类型为 UTL_FILE.FILE_TYPE 的值,用于指示所打开文件的文件句柄。
函数参数
location
类型为 VARCHAR(128) 的输入参数,用于指定包含该文件的目录的别名。
filename
类型为 VARCHAR(255) 的输入参数,用于指定该文件的名称。
open_mode
类型为 VARCHAR(10) 的输入参数,用于指定该文件的打开方式:
a
附加到文件
r
读取文件
w
写入文件
max_linesize
类型为 INTEGER 的可选输入参数,用于指定行的最大大小(以字符为单位)。缺省值为 1024 字节。在读取方式下,如果尝试读取大小超过 max_linesize 的行,那么会抛出异常。在写入和附加方式下,如果尝试写入大小超过 max_linesize 的行,那么会抛出异常。行结束字符不计入行大小。
GET_LINE 过程
GET_LINE 过程从指定的文件获取文本行。该文本行不包括行结束终止符。没有其他要读取的行时,该过程会抛出 NO_DATA_FOUND 异常。
语法
>>-UTL_FILE.GET_LINE--(--file--,--buffer--)--------------------><
过程参数
file
类型为 UTL_FILE.FILE_TYPE 的输入参数,其中包含所打开文件的文件句柄。
buffer
类型为 VARCHAR(32672) 的输出参数,其中包含文件中的文本行。
NEW_LINE 过程
NEW_LINE 过程将行结束字符序列写入指定的文件。
语法
>>-UTL_FILE.NEW_LINE--(--file--+----------+--)-----------------><
'-,--lines-'
过程参数
file
类型为 UTL_FILE.FILE_TYPE 的输入参数,其中包含文件句柄。
lines
类型为 INTEGER 的可选输入参数,用于指定要写入文件的行结束字符序列的数目。缺省值为 1。
PUT 过程
PUT 过程将字符串写入指定的文件。字符串结尾不会写入任何行结束字符序列。
语法
>>-UTL_FILE.PUT--(--file--,--buffer--)-------------------------><
过程参数
file
类型为 UTL_FILE.FILE_TYPE 的输入参数,其中包含文件句柄。
buffer
类型为 VARCHAR(32672) 的输入参数,用于指定要写入文件的文本。
UTL_RAW包
UTL_RAW包是为操作RAW类型数据而设计的包,内容包括以下操作函数。
BIT_AND过程
输出r1与r2的按位运算的逻辑与。即将r1、r2按照二进制顺序排列,进行与运算。如果r1,r2长度不等,则在较短的最后一个字节之后终止AND操作。返回RAW类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
例如:十六进制数a与b,a的二进制为00001010,b的二进制00001011。按位进行逻辑与运算即前四位都是0x0,第五位1x1、第六位0x0、第七位1x1、第八位0x1。最终结果位00001010,转为十六进制即为数0a。
> select utl_raw.bit_and('a','b') c1 from dual;
C1 0A
BIT_COMPLEMENT过程
计算r的按位运算的反码。返回RAW类型。
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
例如:十六进制数a,a的二进制为00001010,按位反码后得到11110101,转为十六进制即为F5.
> select UTL_RAW.BIT_COMPLEMENT('a') c1 FROM DUAL;
C1 F5
1 row(s) retrieved.
BIT_OR过程
输出r1与r2的按位运算的逻辑或。即将r1、r2按照二进制顺序排列,进行或运算。如果r1,r2长度不等,则在较短的最后一个字节之后终止OR操作。返回RAW类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
例如:十六进制数a与b,a的二进制为00001010,b的二进制00001011。按位进行逻辑或运算即前四位都是0+0,第五位1+1、第六位0+0、第七位1+1、第八位0+1。最终结果位00001011,转为十六进制即为数0b。
> SELECT UTL_RAW.BIT_OR('a','b') c1 FROM DUAL;
C1 0B
1 row(s) retrieved.
BIT_XOR过程
输出r1与r2的按位运算的逻辑异或。即将r1、r2按照二进制顺序排列,进行异或运算。如果r1,r2长度不等,则在较短的最后一个字节之后终止XOR操作。返回RAW类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
例如:十六进制数a与b,a的二进制为00001010,b的二进制00001011。按位进行逻辑异或运算即前四位都是0^0,第五位1^1、第六位0^0、第七位1^1、第八位0^1。最终结果为00000001,转为十六进制即为数01。
> SELECT UTL_RAW.BIT_XOR('a','b') c1 FROM DUAL;
C1 01
1 row(s) retrieved.
CAST_FROM_BINARY_DOUBLE过程
将BINARY_DOUBLE类型转化为十六进制数字。返回RAW类型。此函数暂不可用。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | BINARY_DOUBLE类型表达式 | 为BINARY_DOUBLE类型或能通过隐式类型转换为BINARY_DOUBLE类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | 读取r1数据的顺序 | 为数值类型或能通过隐式类型转换为数值类型的表达式,其他数据类型报错,取值范围1,2,3。缺省为1。1表示大端方式,2表示小端方式,3表示使用当前机器的大小端方式。 | 精确数值 |
CAST_FROM_BINARY_FLOAT过程
将BINARY_FLOAT类型转化为十六进制数字。返回RAW类型。此函数暂不可用。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | BINARY_FLOAT类型表达式 | 为BINARY_FLOAT类型或能通过隐式类型转换为BINARY_FLOAT类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | 读取r1数据的顺序 | 为数值类型或能通过隐式类型转换为数值类型的表达式,其他数据类型报错,取值范围1,2,3。缺省为1。1表示大端方式,2表示小端方式,3表示使用当前机器的大小端方式。 | 精确数值 |
CAST_FROM_BINARY_INTEGER过程
将INTEGER类型的十进制数字转为十六进制数字。返回RAW类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | BINARY_INTEGER类型表达式 | 为BINARY_INTEGER类型或能通过隐式类型转换为BINARY_INTEGER类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | 读取r1数据的顺序 | 为数值类型或能通过隐式类型转换为数值类型的表达式,其他数据类型报错,取值范围1,2,3。缺省为1。1表示大端方式,2表示小端方式,3表示使用当前机器的大小端方式。 | 精确数值 |
例如:十进制数字10转化为16进制字后结果为A。
> select utl_raw.cast_from_binary_integer(10) c1 from dual;
C1 0000000A
1 row(s) retrieved.
CAST_FROM_NUMBER过程
将NUMBER类型的十进制数字转为十六进制数字。返回RAW类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | NUMBER类型表达式 | 为NUMBER类型或能通过隐式类型转换为NUMBER类型的表达式,其他数据类型报错。 | 精确数值 |
例如:number类型的十进制数字9的二进制存储值是C10A。其中C1代表标识位。0A表示具体的存储值,对于NUMBER类型是将9+1后存储。
> select UTL_RAW.cast_from_number(9) c1 from dual;
C1 C10A
1 row(s) retrieved.
CAST_TO_BINARY_DOUBLE过程
将十六进制数字转化为十进制数字。返回BINARY_DOUBLE类型。此函数暂不可用。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | 读取r1数据的顺序 | 为数值类型或能通过隐式类型转换为数值类型的表达式,其他数据类型报错,取值范围1,2,3。缺省为1。1表示大端方式,2表示小端方式,3表示使用当前机器的大小端方式。 | 精确数值 |
CAST_TO_BINARY_FLOAT过程
将十六进制数字转化为十进制数字。返回BINARY_FLOAT类型。此函数暂不可用。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | 读取r1数据的顺序 | 为数值类型或能通过隐式类型转换为数值类型的表达式,其他数据类型报错,取值范围1,2,3。缺省为1。1表示大端方式,2表示小端方式,3表示使用当前机器的大小端方式。 | 精确数值 |
CAST_TO_BINARY_INTEGER过程
将十六进制数字转化为十进制数字。返回INTEGER类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | 读取r1数据的顺序 | 为数值类型或能通过隐式类型转换为数值类型的表达式,其他数据类型报错,取值范围1,2,3。缺省为1。1表示大端方式,2表示小端方式,3表示使用当前机器的大小端方式。 | 精确数值 |
例如:将十六进制数字0A转为十进制后得到结果10。
> select UTL_RAW.CAST_TO_BINARY_INTEGER('0a') c1 from dual;
C1
10
1 row(s) retrieved.
CAST_TO_NUMBER过程
将十六进制数字转化为十进制数字。返回NUMBER类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | RAW类型表达式 |
例如:16进制数字C10A转化为10进制NUMBER类型后得到9。跟函数CAST_FROM_NUMBER原理一致。
> select UTL_RAW.CAST_TO_number('C10A') c1 from dual;
C1
9.00000000000000
1 row(s) retrieved.
CAST_TO_RAW过程
将ASCII字符转化为十六进制数字。返回RAW类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | 字符类型表达式 | 为字符类型或能通过隐式类型转换为字符类型的表达式,其他数据类型报错。 | 表达式 |
例如:ASCII字符A对应的10进制数字是65,转为十六进制数字为41。
> select UTL_RAW.CAST_TO_RAW('A') c1 from dual;
C1 41
1 row(s) retrieved.
CAST_TO_VARCHAR2过程
将十六进制数字转化为ASCII字符。返回VARCHAR2类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
例如:十六进制数41,转为10进制为65,转为ASCII为A。
> select UTL_RAW.CAST_TO_VARCHAR2('41') from dual;
C1 A
1 row(s) retrieved.
COMPARE过程
比较十六进制串r1和r2。如果r1串长度<r2串长度,r1串用r3填充。返回INTEGER类型。返回0表示相等,否则返回不相等的起始字节位置。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | 比较表达式1 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | 比较表达式2 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r3 | 需要填充到r1串的表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,缺省为null,其他数据类型报错。 | 表达式 |
例如:使用04填充010103后与01020304作比较。2位作为一组16进制数。差异出现在第2位上。因此返回结果2。
> SELECT utl_raw.compare( '010103', '01020304', '03' ) c1 from dual;
C1
2
1 row(s) retrieved.
CONCAT过程
按照参数顺序分别连接各个十六进制数,最大可连接12个。返回连接后的十六进制数值,返回类型为RAW。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| rn | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。rn最多有12个。 | 表达式 |
例如:将EAAB与3A拼接。
> select UTL_RAW.CONCAT('EAAB','3A') c1 FROM DUAL;
C1 EAAB3A
1 row(s) retrieved.
CONVERT过程
将在r3字符集下的十六进制数字转化为r2字符集下的十六进制数字,返回类型为RAW。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | 转换后字符集 | 为字符类型或能通过隐式类型转换为字符类型的表达式,取值包括:US7ASCII、WE8ISO8859P1、zhs16cgb231280、zhs16gbk、GBK、GB18030、ISO_8859_9、ISO_8859_1。 | 精确字符值 |
| r3 | 转换前字符集 | 为字符类型或能通过隐式类型转换为字符类型的表达式,取值包括:US7ASCII、WE8ISO8859P1、zhs16cgb231280、zhs16gbk、GBK、GB18030、ISO_8859_9、ISO_8859_1。 | 精确字符值 |
例如:先获取当前字符集"好"字的二进制对应的16进制数为E5A5BD,转为ZHS16GBK字符集下为BAC3。
> select utl_raw.cast_to_raw('好') c1 from dual;
C1 E5A5BD
1 row(s) retrieved.
> select UTL_RAW.convert('E5A5BD','ZHS16GBK','UTF8') C1 from dual;
C1 BAC3
1 row(s) retrieved.
> select UTL_RAW.CAST_TO_RAW(convert('好','ZHS16GBK','UTF8')) C1 from dual;
C1 BAC3
1 row(s) retrieved.
8s支持的字符集与转换关系如下:
| convert函数入参字符集 | 8s内部执行对应字符集 |
|---|---|
| US7ASCII | ASCII |
| WE8ISO8859P1 | 8859-1 |
| zhs16cgb231280 | GB2312-80 |
| zhs16gbk | GB18030-2000 |
| GBK | GB18030-2000 |
| GB18030 | GB18030-2000 |
| ISO_8859_9 | 8859-9 |
| ISO_8859_1 | 8859-1 |
COPIES过程
将十六进制串数值拷贝d次,依次排在前一个数的后面。返回新的十六进制数值,返回类型为RAW。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| d | 拷贝的次数 | 数值。当传入小数时会将小数位截掉。最小值为1。 | 数值 |
例如:将十六进制数字1A1B复制三次
> select utl_raw.COPIES('1A1B',3) c1 FROM DUAL;
C1 1A1B1A1B1A1B
1 row(s) retrieved.
LENGTH过程
返回十六进制表达式字节的长度。返回类型为INTEGER。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | 表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
例如:计算十六进制字符串EAEA的长度
> select UTL_RAW.LENGTH('EAEA') c1 FROM DUAL;
C1
2.00000000000000
1 row(s) retrieved.
OVERLAY过程
用十六进制串r1覆盖十六进制串r2。返回RAW类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| r2 | RAW类型表达式 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错。 | 表达式 |
| d1 | 起始位置,即从第几位开始覆盖。 | 为数值类型或能通过隐式类型转换为数值类型的表达式,其他数据类型报错,缺省值为1。 | 精确数值 |
| d2 | r1的使用长度,即用r1的多少字节做填充 | 为数值类型或能通过隐式类型转换为数值类型的表达式,其他数据类型报错,缺省值为null。 | 精确数值 |
| d3 | 若r2的长度小于d2或者d1超过了r2的长度,r2缺少部分会用d3值替代。 | 为RAW类型或能通过隐式类型转换为RAW类型的表达式,其他数据类型报错,缺省值为null。 | 表达式 |
例如:用十六进制字符串AABB覆盖十六进制字符串010203,从第五位开始,因为010203不够5个字节缺失部分用FF代替,取AABB的一个字节AA覆盖。
> select utl_raw.overlay( 'AABB', '010203', 5, 1, 'FF' ) c1 from dual;
C1 010203FFAA
1 row(s) retrieved.
ODCICONST包
ODCICONST 包中定义了一系列适用于8s PL/SQL的常量。下表中列出了 ODCICONST 系统包中的常量。
| 常量 | 值 | 常量 | 值 | 常量 | 值 |
|---|---|---|---|---|---|
| Success | 0 | RowOption | 2 | FirstCall | 1 |
| Error | 1 | EstimateStats | 1 | IntermediateCall | 2 |
| Warning | 2 | ComputeStats | 2 | FinalCall | 3 |
| ErrContinue | 3 | Validate | 4 | RebuildIndex | 4 |
| Fatal | 4 | AlterIndexNone | 0 | RebuildPMO | 5 |
| PredExactMatch | 1 | AlterIndexRename | 1 | StatsGlobal | 6 |
| PredPrefixMatch | 2 | AlterIndexRebuild | 2 | StatsGlobalAndPartition | 7 |
| PredIncludeStart | 4 | AlterIndexRebuildOnline | 3 | StatsPartition | 8 |
| PredIncludeStop | 8 | AlterIndexModifyCol | 4 | FetchOp | 1 |
| PredObjectFunc | 16 | AlterIndexUpdBlockRefs | 5 | PopulateOp | 2 |
| PredObjectPkg | 32 | AlterIndexRenameCol | 6 | Sample | 1 |
| PredObjectType | 64 | AlterIndexRenameTab | 7 | SampleBlock | 2 |
| PredMultiTable | 128 | AlterIndexMigrate | 8 | TRUE | 1 |
| PredNotEqual | 256 | Local | 1 | FALSE | 0 |
| QueryFirstRows | 1 | RangePartn | 2 | QueryCoordinator | 1 |
| QueryAllRows | 2 | HashPartn | 4 | Shadow | 2 |
| QuerySortAsc | 4 | Online | 8 | Slave | 4 |
| QuerySortDesc | 8 | Parallel | 16 | FetchEOS | 1 |
| QueryBlocking | 16 | Unusable | 32 | CompFilterByCol | 1 |
| CleanupCall | 1 | IndexOnIOT | 64 | CompOrderByCol | 2 |
| RegularCall | 2 | TransTblspc | 128 | CompOrderDscCol | 4 |
| ObjectFunc | 1 | FunctionIdx | 256 | CompUpdatedCol | 8 |
| ObjectPkg | 2 | ListPartn | 512 | CompRenamedCol | 16 |
| ObjectType | 4 | UpdateGlobalIndexes | 1024 | CompRenamedTopADT | 32 |
| ArgOther | 1 | DefaultDegree | 32767 | ColumnExpr | 1 |
| ArgCol | 2 | DebuggingOn | 1 | AncOpExpr | 2 |
| ArgLit | 3 | NoData | 2 | SortAsc | 1 |
| ArgAttr | 4 | UserParamString | 4 | SortDesc | 2 |
| ArgNull | 5 | RowMigration | 8 | NullsFirst | 4 |
| ArgCursor | 6 | IndexKeyChanged | 16 | AddPartition | 1 |
| PercentOption | 1 | None | 0 | DropPartition | 2 |
例如:自定义函数,返回odciconst包中定义的常量,并调用函数。
>create or replace function test_f(a in int) return int as
begin
if a>60 then
return odciconst.Success;
else
return odciconst.Error;
end if;
end;
/
>select test_f(100) from dual;
(EXPRESSION)
0
1 row(s) retrieved.
UTL_ENCODE包
UTL_ENCODE包提供了将RAW类型数据进行编码和解码的功能。
BASE64_ENCODE函数
将raw格式的数据r1 编码成base64字符集格式,再以raw类型返回。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | 需要编码为base64字符集格式的数据 | 为RAW类型或能通过隐式类型转换为RAW类型的数据,不能为空。 | 表达式 |
例如:将字符串a编码成base64字符集格式。
> select utl_encode.base64_ENCODE ('a') from dual;
(CONSTANT) 43673D3D
1 row(s) retrieved.
BASE64_DECODE函数
将base64字符集的编码r1 解码成原始的raw数据类型。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| r1 | 需要解码的base64字符集数据 | 为RAW类型或能通过隐式类型转换为RAW类型的数据,不能为空,不能包含非base64字符集数据。 | 表达式 |
例如:将base64字符集格式的数据6D673D3D解码。
> select utl_encode.base64_DECODE ('6D673D3D') from dual;
(CONSTANT) 9A
1 row(s) retrieved.
DBMS_CRYPTO包
DBMS_CRYPTO 包提供加密和解密数据的接口,支持多种分组加密、流加密算法和散列算法。如下详细介绍DBMS_CRYPTO 包中支持的过程和函数:
HASH函数
对 RAW、BLOB、CLOB 数据进行散列,返回raw类型。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| src | 输入参数,需要散列的数据 | 数据类型可以为raw、blob或clob | 表达式 |
| type | 输入参数,使用的算法 | 支持HASH_MD4、HASH_MD5、HASH_SH1、HASH_SH256、HASH_SH384、HASH_SH512 | 表达式 |
例如:将raw类型的字符串'7469676572738923437657274'分别应用HASH_MD5、HASH_SH1算法进行散列处理。
>DECLARE
RAW_INPUT raw(128) := '7469676572738923437657274';
MD5_HASH raw(1024);
SHA1_HASH raw(1024);
BEGIN
MD5_HASH := DBMS_CRYPTO.HASH(RAW_INPUT, DBMS_CRYPTO.HASH_MD5);
DBMS_OUTPUT.PUT_LINE(MD5_HASH);
SHA1_HASH := DBMS_CRYPTO.HASH(RAW_INPUT, DBMS_CRYPTO.HASH_SH1);
DBMS_OUTPUT.PUT_LINE(SHA1_HASH);
END;
/
ENCRYPT函数
ENCRYPT函数用于对RAW 数据进行加密,返回raw数据类型。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| src | 输入参数,需要加密的数据 | raw数据类型 | 表达式 |
| type | 输入参数,使用的算法 | 支持分组加密算法和流加密算法。 1)使用分组加密算法时必须同时指定加密算法、工作模式、填充模式。书写规则为:加密算法 + 工作模式 + 填充模式。 支持的分组加密算法:ENCRYPT_DES、ENCRYPT_3DES、ENCRYPT_3DES_2KEY、ENCRYPT_AES128、ENCRYPT_AES192、ENCRYPT_AES256。 支持的工作模式:CHAIN_ECB、CHAIN_CBC、CHAIN_CFB、CHAIN_OFB。 支持的填充模式:PAD_PKCS5、PAD_NONE、PAD_ZERO。 支持的分组密码套件:DES_CBC_PKCS5和DES3_CBC_PKCS5。 2)流加密算法支持ENCRYPT_RC4。仅需要指定算法名称即可。 | 表达式 |
| key | 输入参数,加密使用的key | key 长度必须足够,大于等于算法所需密钥长度,超出长度部分忽略,长度不足将会报错处理。 | 表达式 |
| iv | 输入参数,加密使用的初始向量 | 默认为空 | 表达式 |
DECRYPT函数
DECRYPT函数用于对RAW 数据进行解密,返回raw数据类型。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| src | 输入参数,需要解密的数据 | raw数据类型 | 表达式 |
| type | 输入参数,使用的算法 | 同encrypt函数 | 表达式 |
| key | 输入参数,解密使用的key | 同encrypt函数 | 表达式 |
| iv | 输入参数,解密使用的初始向量 | 默认为空 | 表达式 |
例如:将RAW类型的字符串 '7469676572738923437657274'加密后解密。采用分组加密算法ENCRYPT_AES256,工作模式采用CHAIN_CBC,填充模式采用PAD_PKCS5。
>DECLARE
raw_input raw(128) := '7469676572738923437657274';
encrypted_raw RAW (2000);
decrypted_raw RAW (2000);
key_bytes_raw RAW (32);
encryption_type PLS_INTEGER :=
DBMS_CRYPTO.ENCRYPT_AES256
+ DBMS_CRYPTO.CHAIN_CBC
+ DBMS_CRYPTO.PAD_PKCS5;
iv_raw RAW (16);
BEGIN
DBMS_OUTPUT.PUT_LINE ( 'Original string: ' || raw_input);
key_bytes_raw := DBMS_CRYPTO.RANDOMBYTES (32);
iv_raw := DBMS_CRYPTO.RANDOMBYTES (16);
encrypted_raw := DBMS_CRYPTO.ENCRYPT
(
raw_input,
encryption_type,
key_bytes_raw,
iv_raw
);
DBMS_OUTPUT.PUT_LINE ('Encrypted string: ' || encrypted_raw);
decrypted_raw := DBMS_CRYPTO.DECRYPT
(
encrypted_raw,
encryption_type,
key_bytes_raw,
iv_raw
);
DBMS_OUTPUT.PUT_LINE ('Decrypted string: ' || decrypted_raw);
END;
/
ENCRYPT过程
ENCRYPT过程用于对BLOB、CLOB数据进行加密。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dst | 输入输出参数,加密后的数据 | 表达式 | |
| src | 输入参数,需要加密的数据 | blob或clob数据类型 | 表达式 |
| type | 输入参数,使用的算法 | 同encrypt函数 | 表达式 |
| key | 输入参数,解密使用的key | 同encrypt函数 | 表达式 |
| iv | 输入参数,解密使用的初始向量 | 默认为空 | 表达式 |
DECRYPT过程
DECRYPT过程用于对BLOB、CLOB数据进行解密。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dst | 输入输出参数,解密后的数据 | 表达式 | |
| src | 输入参数,需要解密的数据 | blob或clob数据类型 | 表达式 |
| type | 输入参数,使用的算法 | 同encrypt函数 | 表达式 |
| key | 输入参数,解密使用的key | 同encrypt函数 | 表达式 |
| iv | 输入参数,解密使用的初始向量 | 默认为空 | 表达式 |
例如:将clob类型的字符串 '7469676572738923437657274'加密后解密。采用分组加密算法ENCRYPT_AES256,工作模式采用CHAIN_CBC,填充模式采用PAD_PKCS5。
>DECLARE
src_input clob := '7469676572738923437657274';
dst_output blob:='1';
dst_len int:=1024;
src_len int:=1024;
key_bytes_raw RAW (32);
encrypted_raw RAW (2000);
decrypted_raw VARCHAR2 (2000);
encryption_type PLS_INTEGER :=
DBMS_CRYPTO.ENCRYPT_AES256
+ DBMS_CRYPTO.CHAIN_CBC
+ DBMS_CRYPTO.PAD_PKCS5;
iv_raw RAW (16);
BEGIN
DBMS_OUTPUT.PUT_LINE ( 'Original string: ' || src_input);
key_bytes_raw := DBMS_CRYPTO.RANDOMBYTES (32);
iv_raw := DBMS_CRYPTO.RANDOMBYTES (16);
DBMS_CRYPTO.ENCRYPT
(
dst_output,
src_input,
encryption_type,
key_bytes_raw,
iv_raw
);
dbms_lob.read(dst_output,dst_len,1,encrypted_raw);
dbms_output.put_line(encrypted_raw);
DBMS_CRYPTO.DECRYPT
(
src_input,
dst_output,
encryption_type,
key_bytes_raw,
iv_raw
);
dbms_lob.read(src_input,src_len,1,decrypted_raw);
dbms_output.put_line(decrypted_raw);
END;
/
MAC函数
MAC函数将MAC算法应用于数据,以提供密钥信息保护。返回RAW类型。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| src | 输入参数,要应用MAC算法的源数据 | RAW、BLOB、CLOB类型 | 表达式 |
| type | 输入参数,使用的算法 | 支持HMAC_MD5、HMAC_SH1、HMAC_SH256、HMAC_SH384、HMAC_SH512 | 表达式 |
| key | 输入参数,应用MAC算法的密钥 | key 长度必须足够,大于等于算法所需密钥长度,超出长度部分忽略,长度不足将会报错处理。 | 表达式 |
例如:将mac算法应用于raw类型的字符串'7469676572738923437657274',算法分别采用HMAC_MD5和HMAC_SH256。
>DECLARE
SRC RAW(200);
KEY RAW(200);
BEGIN
SRC:='7469676572738923437657274';
KEY:='1122330066';
DBMS_OUTPUT.PUT_LINE(DBMS_CRYPTO.MAC(SRC,DBMS_CRYPTO.HMAC_MD5,KEY));
DBMS_OUTPUT.PUT_LINE(DBMS_CRYPTO.MAC(SRC,DBMS_CRYPTO.HMAC_SH256,KEY));
END;
/
RANDOMBYTES函数
RANDOMBYTES函数生成一个raw类型的伪随机序列,为一个十六进制的随机数。
语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| number_bytes | 生成的伪随机序列的字节数 | 不应超过RAW变量的最大长度 | 表达式 |
例如:生成一个raw类型的10字节的伪随机序列。
>begin
dbms_output.put_line(dbms_crypto.randominteger);
end;
/
RANDOMINTEGER函数
RANDOMINTEGER函数返回可用于BINARY_INTEGER数据类型的完整范围内的整数。
语法:

例如:
begin
dbms_output.put_line(dbms_crypto.randominteger);
end;
/
RANDOMNUMBER函数
RANDOMNUMBER函数返回一个decimal(16)的随机数值。
语法:

例如:
>begin
dbms_output.put_line(dbms_crypto.randomnumber);
end;
/
DBMS_JOB包
该包提供了一组接口,用于实现调度和管理作业队列中的作业,即实现对定时任务的调度和管理。目前支持的方法有submit、change、what、next_date、interval、broken、run、remove。定时任务执行记录会打印在online日志中。
说明及限制:
使用该系统包时需拥有sysadmin系统库的连接权限。
jobid与interval的长度和不超过25位,否则报错。
目前定时任务的作业内容的语法格式是SQL语法而不是PLSQL语法。
目前定时任务的作业内容长度限制为2048。
目前submit方法在提交任务时jobid为空会报错。
定时任务信息存储在sysadmin库的ph_task表中。
SUBMIT
该方法用来提交作业。
dbms_job.submit(
job out integer,
what in lvarchar,
next_date in datetime year to second default sysdate,
interval in lvarchar default 'null',
no_parse in boolean default false,
instance in integer default 0,
force in boolean default false
);
参数说明:
job:出参,提交任务的jobid号。
what:为作业执行的任务。
next_date:为作业的下次执行时间。
interval:为作业的执行间隔。
no_parse:无意义,语法支持。
instance:无意义,语法支持。
force:无意义,语法支持。
应用样例:
> declare
job int;
begin
job :=0;
dbms_job.submit(
job
,'insert into t1 values(1);'
,sysdate
,'sysdate+1/(24*60)'
);
dbms_output.put_line('jobid:= '||job);
end ;
> /
PL/SQL procedure successfully completed.
jobid:= 62
CHANGE
该方法用来修改已提交的作业。
dbms_job.change(
job in integer,
next_date in datetime year to second,
interval in lvarchar,
instance in integer default 0,
force in boolean default false
);
参数说明:
job:入参,需要修改的任务的jobid号。
what:为作业执行的新任务。
next_date:为作业的下次执行时间。
interval:为作业的执行间隔。
instance:无意义,语法支持。
force:无意义,语法支持。
应用样例:
> declare
job int:=62;
begin
dbms_job.change(
job
,'insert into t1 values(2);'
,sysdate
,'sysdate+1/(24*60)'
);
dbms_output.put_line('jobid:= '||job);
end ;
> /
PL/SQL procedure successfully completed.
jobid:= 62
WHAT
该方法更改作业的执行任务。
dbms_job.what(
job in integer,
what in lvarchar
);
参数说明:
job:出参,提交任务的jobid号。
what:为作业执行的任务。
应用样例:
> declare
job int:=62;
begin
dbms_job.what(
job
,'insert into t1 values(3);'
);
dbms_output.put_line('jobid:= '||job);
end ;
> /
PL/SQL procedure successfully completed.
jobid:= 62
NEXT_DATE
该方法用来更改作业的下次执行时间。
dbms_job.next_date(
job in integer,
next_date in datetime year to second
);
参数说明:
job:入参,需要修改的任务的jobid号。
next_date:为作业的下次执行时间。
应用样例:
> declare
job int:=62;
begin
dbms_job.next_date(
job
,sysdate +1
);
dbms_output.put_line('jobid:= '||job);
end ;
> /
PL/SQL procedure successfully completed.
jobid:= 62
INTERVAL
该方法用来更改作业的执行间隔。
dbms_job.next_date(
job in integer,
interval in lvarchar
);
参数说明:
job:入参,需要修改的任务的jobid号。
interval:为作业的执行间隔。
应用样例:
> declare
job int:=62;
begin
dbms_job.interval(
job
,'sysdate +2/(24*60)'
);
dbms_output.put_line('jobid:= '||job);
end ;
> /
PL/SQL procedure successfully completed.
jobid:= 62
BROKEN
该方法用来更改作业的启停状态。
dbms_job.broken(
job in integer,
broken in boolean,
next_date in datetime year to second default sysdate
);
参数说明:
job:入参,需要修改的任务的jobid号。
broken:为作业需要更改的状态,true或者false。
next_date:为作业broken状态后的下次执行时间。
应用样例:
> declare
job int:=62;
begin
dbms_job.broken(
job
,true
,sysdate +2
);
dbms_output.put_line('jobid:= '||job);
end ;
> /
PL/SQL procedure successfully completed.
jobid:= 62
RUN
该方法用来立即执行作业任务。
dbms_job.run(
job in integer,
force in boolean default false
);
参数说明:
job:入参,需要立即执行的任务的jobid号。
force:无意义,语法支持。
应用样例:
> declare
job int:=62;
begin
dbms_job.run(
job
);
dbms_output.put_line('jobid:= '||job);
end ;
> /
PL/SQL procedure successfully completed.
jobid:= 62
REMOVE
该方法用来删除作业。
dbms_job.remove(
job in integer
);
参数说明:
job:入参,需要修改的任务的jobid号。
应用样例:
> declare
job int:=62;
begin
dbms_job.remove(
job
);
dbms_output.put_line('jobid:= '||job);
end ;
> /
PL/SQL procedure successfully completed.
jobid:= 62
DBMS_TRANSCATION
获取当前活动事务号。若当前在事务内返回事务号,若不在事务内,返回空。
dbms_transaction.local_transaction_id()
应用样例:
> select dbms_transaction.local_transaction_id() from dual;
(EXPRESSION) 225.7
1 row(s) retrieved.
DBMS_MVIEWS
此包提供了对物化视图操作的一些方法,如refresh、refresh_all、refresh_all_mviews、refresh_dependent。
REFRESH
同时刷新一个或者多个物化视图。
dbms_job.refresh(
list in varchar2,
method in varchar2 default null,
rollback_seg in varchar2 default true,
refresh_after_errors in boolean default false,
purge_option in integer default 0,
parallelism in integer default 0,
heap_size in integer default 0,
atomic_refresh in boolean default true,
nested in boolean default false
);
参数说明:
list:指定要刷新的物化视图名称,多个物化视图名称用逗号隔开。
method:物化视图刷新方式,'f'表示快速刷新,'c'表示完全刷新,空为默认刷新方式。
rollback_seg:语法兼容。
refresh_after_errors:语法兼容。
purge_option:语法兼容。
parallelism in:语法兼容。
heap_size:语法兼容。
atomic_refresh:语法兼容。
nested:语法兼容。
应用样例:
--准备数据
> create table t1(c1 int,name varchar(200));
Table dropped.
> insert into t1 values(1,'zhansgan1');
1 row(s) inserted.
> insert into t1 values(1,'zhansgan2');
1 row(s) inserted.
--创建预期更新的物化视图
> create materialized view mv1 build deferred as select * from t1;
View created.
> create materialized view mv2 build deferred as select * from t1;
View created.
--使用dbms_view包刷新
> declare
begin
dbms_mview.refresh(list=>'mv1,mv2',method=>'c');
end;
/
PL/SQL procedure successfully completed.
REFRESH_ALL
刷新所有的实例上所有物化视图。
dbms_job.refresh_all
应用样例:
--使用dbms_view包刷新所有物化视图
> declare
begin
dbms_mview.refresh_all;
end;
/
PL/SQL procedure successfully completed.
REFRESH_ALL_MVIEWS
刷新具有特定属性的所有物化视图。
dbms_job.refresh_all_mviews(
failures out integer,
method in varchar2 default null,
rollback_seg in varchar2 default true,
refresh_after_errors in boolean default false,
atomic_refresh in boolean default true,
out_of_replace boolean default true
);
参数说明:
failure:返回处理过程是否发生错误。
method:物化视图刷新方式,'f'表示快速刷新,'c'表示完全刷新,空为默认刷新方式。
rollback_seg:语法兼容。
refresh_after_errors:语法兼容。
atomic_refresh:语法兼容。
out_of_replace:语法兼容。
应用样例:
> declare
failure int;
begin
dbms_mview.refresh_all_mviews(failure,method=>'c');
dbms_output.put_line(failure);
end;
/> > > > > >
PL/SQL procedure successfully completed.
0
REFRESH_DEPENDENT
用于刷新依赖与基表的所有物化视图。
dbms_mviews.refresh_dependent(
failure out integer,
tab in varchar2,
method in varchar2 default null,
rollback_seg in varchar2 default true,
refresh_after_errors in boolean default false,
atomic_refresh in boolean default true,
out_of_place boolean defalue true
);
参数说明:
failure:返回处理过程是否发生错误。
tab:物化视图所依赖的主表名称,所有视图必须位于本地数据库中,且创建时有创建物化视图日志表。
method:物化视图刷新方式,'f'表示快速刷新,'c'表示完全刷新,空为默认刷新方式。
rollback_seg:语法兼容。
refresh_after_errors:语法兼容。
atomic_refresh:语法兼容。
out_of_replace:语法兼容。
应用样例:
> declare
failure int;
begin
dbms_mview.refresh_dependent(failure,'t1',method=>'c');
dbms_output.put_line(failure);
end;
> /
PL/SQL procedure successfully completed.
0
DBMS_SCHEDULER
该包提供了一组与作业调度相关的存储过程和方法,用于实现调度和管理作业队列中的作业,该包复用了8s定时任务机制,作业相关信息存储在sysadmin系统库下的ph_task表中。目前支持的方法有:generate_job_name、create_job、run_job、enable、disable、set_attribute、drop_job。
说明及限制:
使用该系统包时需拥有sysadmin系统库的连接权限。
作业名job_name长度最大值为36,格式必须为dbms_schedule$_{N},否则为无效job_name。
作业执行SQL语句job_action最大长度为2048。
generate_job_name
返回一个唯一的作业名。格式为prefix_N,N为作业队列中最大作业id+1。
dbms_schedule.generate_job_name(prefix in lvarchar default 'dbms_schedule$_')
参数说明:
prefix:作业名中的前缀。
应用样例:
declare
v_job_name varchar2(36);
begin
v_job_name := dbms_scheduler.generate_job_name('dbms_scheduler$_');
dbms_scheduler.create_job(v_job_name,'','insert into t1 values(1,'|| '123' ||');' );
dbms_scheduler.drop_job(v_job_name,true);
end;
> /
PL/SQL procedure successfully completed.
create_job
创建一个作业。
dbms_scheduler.create_job(
job_name in lvarchar,
job_type in lvarchar default null,
job_action in lvarchar,
number_of_arguments in integer default 0
start_date in datetime hour to second default null
repeat_interval in interval day to second default null
end_date in datetime hour to second default null
job_class in lvarchar default 'default_job_class'
enabled in boolean default false
auto_drop in boolean default true
comments in lvarchar default null
credential_name in lvarchar default null
destination_name in lvarchar default null
);
参数说明:
job_name:作业名称。要求唯一,可由generate_job_name方法生成。
job_type:仅语法兼容。
job_action:作业执行的SQL语句。
number_of_arguments:仅语法兼容。
start_date:作业开始时间。
repeat_interval:作业重复执行的时间间隔。
end_date:作业结束时间。
job_class:仅语法兼容。
enabled:指定作业是否启用。
auto_drop:仅语法兼容。
comments:关于该作业的描述参数。
credential_name:仅语法兼容。
destination_name:仅语法兼容。
应用样例:
declare
v_job_name varchar2(36);
begin
v_job_name := dbms_scheduler.generate_job_name('dbms_scheduler$_');
dbms_scheduler.create_job(v_job_name,'','insert into t1 values(1,'|| '123' ||');' );
dbms_scheduler.drop_job(v_job_name,true);
end;
> /
PL/SQL procedure successfully completed.
run_job
立即执行一次作业。
dbms_scheduler.run_job(
job_name in lvarchar,
use_current_session in boolean default 'true';
)
参数说明:
job_name:待运行的作业名。
use_current_session仅语法兼容。
应用样例:
declare
v_job_name varchar2(36);
begin
v_job_name := dbms_scheduler.generate_job_name('dbms_scheduler$_');
dbms_scheduler.create_job(v_job_name,'','insert into t1 values(1,'|| '123' ||');' );
dbms_scheduler.run_job(v_job_name);
dbms_scheduler.drop_job(v_job_name,true);
end;
> /
PL/SQL procedure successfully completed.
enable
启动作业。
dbms_scheduler.enable(
job_name in lvarchar,
commit_semantis in lvarchar default 'stop_on_first_error'
);
参数说明:
job_name:待运行的作业名。
commit_semantis仅语法兼容。
应用样例:
declare
v_job_name varchar2(36);
begin
v_job_name := dbms_scheduler.generate_job_name('dbms_scheduler$_');
dbms_scheduler.create_job(v_job_name,'','insert into t1 values(1,'|| '123' ||');' );
dbms_scheduler.enable(v_job_name);
dbms_scheduler.drop_job(v_job_name,true);
end;
> /
PL/SQL procedure successfully completed.
disable
禁用作业。
dbms_scheduler.disable(
job_name in lvarchar,
force in boolean default false
commit_semantis in lvarchar default 'stop_on_first_error'
);
参数说明:
job_name:待运行的作业名。
force:仅语法兼容。
commit_semantis:仅语法兼容。
应用样例:
declare
v_job_name varchar2(36);
begin
v_job_name := dbms_scheduler.generate_job_name('dbms_scheduler$_');
dbms_scheduler.create_job(v_job_name,'','insert into t1 values(1,'|| '123' ||');' );
dbms_scheduler.disable(v_job_name);
dbms_scheduler.drop_job(v_job_name,true);
end;
> /
PL/SQL procedure successfully completed.
set_attribute
设置作业属性。
dbms_scheduler.set_attribute(
job_name in lvarchar,
attribute in lvarchar,
values in {interval day to second|lvarchar|datetime hour to second}
);
参数说明:
job_name:待运行的作业名。
attribute:作业的属性名称,仅支持comments、job_action、start_date、end_date、repeat_interval其他属性仅语法兼容。
value:要设置的属性值。
应用样例:
declare
v_job_name varchar2(36);
begin
v_job_name := dbms_scheduler.generate_job_name('dbms_scheduler$_');
dbms_scheduler.create_job(v_job_name,'','insert into t1 values(1,'|| '123' ||');' );
dbms_scheduler.set_attribute(v_job_name,'comments','dasfds');
dbms_scheduler.drop_job(v_job_name,true);
end;
> /
PL/SQL procedure successfully completed.
drop_job
删除作业。
dbms_scheduler.drop_job(
job_name in lvarchar,
force in boolean,
defer in boolean
commit_semantics in lvarchar default 'stop_on_first_error'
);
参数说明:
job_name:待运行的作业名。
force:仅语法兼容。
defer:仅语法兼容。
commit_semantis:仅语法兼容。
应用样例:
declare
v_job_name varchar2(36);
begin
v_job_name := dbms_scheduler.generate_job_name('dbms_scheduler$_');
dbms_scheduler.create_job(v_job_name,'','insert into t1 values(1,'|| '123' ||');' );
dbms_scheduler.set_attribute(v_job_name,'comments','dasfds');
dbms_scheduler.drop_job(v_job_name,true);
end;
> /
PL/SQL procedure successfully completed.